Translations: Russian
This 365 days, the controversy of town was AI and the way in which it’s going to enact the entirety for you.
I love it when somebody or something does the entirety for me. To this end, I made a decision to ask ChatGPT to write my Contemporary Year’s put up:
“Hello ChatGPT. Are you able to put in power a immense language model in SQL?”
“No, SQL is now not honest for implementing immense language units. SQL is a language for managing and querying knowledge in relational databases. Imposing a language model requires advanced algorithms, immense datasets, and assuredly deep studying frameworks, which are beyond the capabilities of SQL.”
It actual proves that when you happen to perceive to procure something carried out appropriate, you can must enact it your self.
Encouraged by this optimistic forecast, at present we can put in power a immense language model in SQL.

Thought
Whereas penning this put up, I weak the improbable article GPT in 60 Traces of NumPy by Jay Mody. This article explains the interior workings of a GPT model powerful better than I’m in a position to hope to enact. Serene, a minute bit recap is in expose.
What is a generative immense language model from a technical standpoint?
A generative LLM is a feature. It takes a textual bid material string as input (known as “suggested” in AI parlance), and returns an array of strings and numbers. This is what the signature of this selection appears to be like adore:
llm(suggested: str) -> list[tuple[str, float]]
This option is deterministic. It does loads of math beneath the hood, nonetheless all this math is hardwired. When you happen to name it many cases with the identical input, this is in a position to presumably well constantly return the identical output.
It could presumably well attain as a shock to anybody who’s been the utilization of ChatGPT and similar products on legend of they can give pretty a pair of solutions to the identical ask. But, it’s merely. We will most likely be in a position to quickly glance how it works.
What are the values this selection returns?
One thing adore this:
llm("I wish you a ecstatic Contemporary")
0 (' Year', 0.967553)
1 (' Years', 0.018199688)
2 (' 365 days', 0.003573329)
3 (' York', 0.003114716)
4 (' Contemporary', 0.0009022804)
…
50252 (' carbohyd', 2.3950911e-15)
50253 (' volunte', 2.2590102e-15)
50254 ('pmwiki', 1.369229e-15)
50255 (' proport', 1.1198108e-15)
50256 (' cumbers', 7.568147e-17)
It returns an array of tuples. Every tuple consists of a notice (or, reasonably, a string) and a host. The number is the probability that this notice will proceed the suggested. The model “thinks” that the phrase “I wish you a ecstatic Contemporary” will most likely be followed by the personality sequence ” Year” with a probability of 96.7%, ” Years” of 1.8% etc.
The notice “deem” above is quoted on legend of, undoubtedly, the model doesn’t in actuality deem. It mechanically returns arrays of phrases and numbers in keeping with some hardwired interior logic.
If it’s that lifeless and deterministic, how can it generate pretty a pair of texts?
Huge language units are weak in textual bid material functions (chatbots, bid material mills, code assistants etc). These functions many cases name the model and procure the notice urged by it (with some stage of randomness). The subsequent urged notice is added to the suggested and the model is named again. This continues in a loop till ample phrases are generated.
The accumulated sequence of phrases will glimpse adore a textual bid material in a human language, total with grammar, syntax and even what looks to be intelligence and reasoning. On this component, it’s miles now not now not like a Markov chain which works on the identical precept.
The internals of a immense language model are wired up in relate that the following urged notice will most likely be a natural continuation of the suggested, total with its grammar, semantics and sentiment. Equipping a feature with such a logic grew to turn into possible thru a series of scientific breakthroughs (and programming drudgery) that procure resulted within the trend of the family of algorithms is named GPT, or Generative Pre-trained Transformer.
What does “Generative Pre-trained Transformer” indicate?
“Generative” manner that it generates textual bid material (by in conjunction with continuations to the suggested recursively, as we seen earlier).
“Transformer” manner that it uses a snort variety of neural network, first developed by Google and described in this paper.
“Pre-trained” is a minute bit bit historical. At the muse, the flexibility for the model to proceed textual bid material was regarded as actual a prerequisite for a extra specialized job: inference (finding logical connections between phrases), classification (for occasion, guessing the choice of stars in a hotel ranking from the textual bid material of the overview), machine translation etc. It was concept that these two parts will deserve to had been trained individually, the language portion being actual a pre-training for a “right” job that will presumably well practice.
Because the conventional GPT paper puts it:
We show camouflage that immense gains on these tasks will most likely be realized by generative pre-training of a language model on a various corpus of unlabeled textual bid material, followed by discriminative vibrant-tuning on every explicit job.
It was now not till later that folks realized that, with a model immense ample, the second step was assuredly now not well-known. A Transformer model, trained to enact nothing else than generate texts, turned out so that it’s essential to practice human language instructions that were contained in these texts, without a extra training (“vibrant-tuning” in AI parlance) required.
With that out of the trend, let’s focus on the implementation.
Generation
Right here is what occurs when we attempt to generate textual bid material from the suggested the utilization of GPT2:
def generate(suggested: str) -> str:
# Transforms a string accurate into a list of tokens.
tokens = tokenize(suggested) # tokenize(suggested: str) -> list[int]
while Upright:
# Runs the algorithm.
# Returns tokens' possibilities: a list of 50257 floats, in conjunction with up to 1.
candidates = gpt2(tokens) # gpt2(tokens: list[int]) -> list[float]
# Selects the following token from the list of candidates
next_token = select_next_token(candidates)
# select_next_token(candidates: list[float]) -> int
# Append it to the list of tokens
tokens.append(next_token)
# Purchase if we must shatter generating.
# It is going to be token counter, timeout, stopword or something else.
if should_stop_generating():
damage
# Transform the list of tokens accurate into a string
completion = detokenize(tokens) # detokenize(tokens: list[int]) -> str
return completion
Let’s put in power all these pieces one after the other in SQL.
Tokenizer
Sooner than a textual bid material will most likely be fed to a neural network, it wishes to be converted accurate into a list of numbers. Clearly, that’s barely news: that is what textual bid material encodings adore Unicode enact. Straightforward Unicode, on the different hand, doesn’t in actuality work well with neural networks.
Neural networks, at their core, enact loads of matrix multiplications and bewitch no topic predictive powers they procure within the coefficients of these matrixes. A majority of these matrixes procure one row per every possible heed within the “alphabet”; others procure one row per “personality”.
Right here, the phrases “alphabet” and “personality” damage now not procure the in trend meaning. In Unicode, the “alphabet” is 149186 characters long (that is how many pretty a pair of Unicode points there are at the time of this writing), and a “personality” will most likely be something adore this: ﷽ (yes, that’s a single Unicode point number 65021, encoding a entire phrase in Arabic that’s extremely crucial for the Muslims). Demonstrate that the right similar phrase could presumably well had been written in in trend Arabic letters. It manner that the identical textual bid material can procure many encodings.
As an illustration, let’s hang the notice “PostgreSQL”. If we were to encode it (convert to an array of numbers) the utilization of Unicode, we would get 10 numbers that will presumably well potentially be from 1 to 149186. It manner that our neural network would must store a matrix with 149186 rows in it and label a name of calculations on 10 rows from this matrix. A majority of these rows (equivalent to the letters of the English alphabet) would be weak lots and pack loads of knowledge; others, adore poop emoji and obscure symbols from tiring languages, would hardly be weak in any respect, nonetheless aloof possess put.
Naturally, we must lend a hand each and each these numbers, the “alphabet” dimension and the “personality” depend, as minute as possible. Ideally, all of the “characters” in our alphabet have to be dispensed uniformly, and we aloof need our encoding to be as highly efficient as Unicode.
The trend we can enact that, intuitively, is to place extraordinary numbers to sequences of phrases that occur assuredly within the texts we work with. In Unicode, the identical non secular phrase in Arabic will most likely be encoded the utilization of both a single code point, or letter by letter. Since we’re rolling our possess encoding, we can enact the identical for the phrases and phrases which could well presumably well be crucial for the model (i.e. demonstrate up assuredly in texts).
As an illustration, we could presumably well procure separate numbers for “Post”, “greSQL” and “ing”. This form, the phrases “PostgreSQL” and “Posting” would each and each procure a dimension of two in our illustration. And undoubtedly, we would aloof lend a hand separate code points for shorter sequences and particular particular person bytes. Although we bump into gibberish or a textual bid material in a foreign language, it could presumably well aloof be encodable, albeit longer.
GPT2 uses a variation of the algorithm known as Byte pair encoding to enact precisely that. Its tokenizer uses a dictionary of 50257 code points (in AI parlance, “tokens”) that correspond to pretty a pair of byte sequences in UTF-8 (plus the “end of textual bid material” as a separate token).
This dictionary was constructed by statistical analysis performed adore this:
- Start with a easy encoding of 256 tokens: one token per byte.
- Take a immense corpus of texts (ideally the one the model will most likely be trained on).
- Encode it.
- Calculate which pair of tokens is the most frequent. Let’s maintain it’s 0x20 0x74 (put followed by the lowercase “t”).
- Establish the following accessible heed (257) to this pair of bytes.
- Repeat the steps 3-5, now being attentive to the byte sequences. If a series of bytes will most likely be encoded with a advanced token, use the advanced token. If there are ambiguities (teach, “abc” can, one day, be encoded as “a” + “bc” or “ab” + “c”), use the one with the lowest number (on legend of it was added earlier and as a consequence of this truth is extra frequent). Plot this recursively till all sequences that can crumple accurate into a single token will crumple accurate into a single token.
- Make the crumple 50000 cases over.
The number 50000 was chosen variety of arbitrarily by the builders. Diversified units lend a hand the choice of tokens within the same vary (from 30k to 100k).
At every iteration of this algorithm, a brand new token that’s a concatenation of two earlier ones will most likely be added to the dictionary. In the shatter, we can end up with 50256 tokens. Add a mounted-number token for “end-of-textual bid material”, and we’re carried out.
The GPT2 version of BTE has one other layer of encoding: the token dictionary maps tokens to strings and now not arrays of bytes. Mapping from bytes to string characters is defined in this selection. We will most likely be in a position to place the dictionary it produces within the table encoder.
Let’s glance how we can put in power the tokenizer in SQL.
The tokenizer is an integral portion of GPT2, and the token dictionary will most likely be downloaded from OpenAI’s web way alongside with the relaxation of the model. We will most likely be in a position to must import it into the table tokenizer. At the bottom of this put up, you are going to procure a hyperlink to the code repository. Its code will automate populating database tables wished for the model.
In a recursive CTE, we can split this notice into tokens (beginning with single bytes) and merge the right adjoining pairs, till there is nothing left to merge. The merging itself occurs in a nested recursive CTE.
For the demo, I will use the notice “Mississippilessly”. Every file within the resultset presentations the right pair to crumple figured out thus some distance, and likewise the progress thru the ask.
WITH RECURSIVE
bpe AS
(
SELECT (n + 1)::BIGINT AS way, personality, TRUE AS proceed, 1 AS step,
NULL::INT AS token, NULL::TEXT AS blended
FROM CONVERT_TO('Mississippilessly', 'UTF-8') AS bytes
CROSS JOIN LATERAL
GENERATE_SERIES(0, LENGTH(bytes) - 1) AS n
JOIN encoder
ON byte = GET_BYTE(bytes, n)
UNION ALL
(
WITH RECURSIVE
bad AS
(
SELECT FROM bpe
WHERE proceed
),
bn AS
(
SELECT ROW_NUMBER() OVER (ORDER BY way) AS way,
proceed,
personality,
personality || LEAD(personality) OVER (ORDER BY way) AS cluster
FROM bad
),
top_rank AS
(
SELECT tokenizer.FROM bn
CROSS JOIN LATERAL
(
SELECT FROM tokenizer
WHERE tokenizer.cluster = bn.cluster
LIMIT 1
) tokenizer
ORDER BY
token
LIMIT 1
),
breaks AS
(
SELECT 0::BIGINT AS way, 1 AS dimension
UNION ALL
SELECT bn.way,
CASE WHEN token IS NULL THEN 1 ELSE 2 END
FROM breaks
JOIN bn
ON bn.way = breaks.way + dimension
LEFT JOIN
top_rank
USING (cluster)
)
SELECT way, personality, token IS NOT NULL,
(SELECT step + 1 FROM bad LIMIT 1), token, top_rank.cluster
FROM breaks
LEFT JOIN
top_rank
ON 1 = 1
CROSS JOIN LATERAL
(
SELECT STRING_AGG(personality, '' ORDER BY way) AS personality
FROM bn
WHERE bn.way >= breaks.way
AND bn.way < breaks.position + length
) bn
WHERE position > 0
)
)
SELECT step, MAX(token) AS token, MAX(blended) AS blended, ARRAY_AGG(personality ORDER BY way)
FROM bpe
WHERE continueGROUP BY
step
ORDER BY
step
| step | token | blended | array_agg |
|---|---|---|---|
| 1 | None | None | [‘M’, ‘i’, ‘s’, ‘s’, ‘i’, ‘s’, ‘s’, ‘i’, ‘p’, ‘p’, ‘i’, ‘l’, ‘e’, ‘s’, ‘s’, ‘l’, ‘y’] |
| 2 | 271 | is | [‘M’, ‘is’, ‘s’, ‘is’, ‘s’, ‘i’, ‘p’, ‘p’, ‘i’, ‘l’, ‘e’, ‘s’, ‘s’, ‘l’, ‘y’] |
| 3 | 274 | es | [‘M’, ‘is’, ‘s’, ‘is’, ‘s’, ‘i’, ‘p’, ‘p’, ‘i’, ‘l’, ‘es’, ‘s’, ‘l’, ‘y’] |
| 4 | 306 | ly | [‘M’, ‘is’, ‘s’, ‘is’, ‘s’, ‘i’, ‘p’, ‘p’, ‘i’, ‘l’, ‘es’, ‘s’, ‘ly’] |
| 5 | 346 | il | [‘M’, ‘is’, ‘s’, ‘is’, ‘s’, ‘i’, ‘p’, ‘p’, ‘il’, ‘es’, ‘s’, ‘ly’] |
| 6 | 381 | pp | [‘M’, ‘is’, ‘s’, ‘is’, ‘s’, ‘i’, ‘pp’, ‘il’, ‘es’, ‘s’, ‘ly’] |
| 7 | 408 | ess | [‘M’, ‘is’, ‘s’, ‘is’, ‘s’, ‘i’, ‘pp’, ‘il’, ‘ess’, ‘ly’] |
| 8 | 747 | iss | [‘M’, ‘iss’, ‘iss’, ‘i’, ‘pp’, ‘il’, ‘ess’, ‘ly’] |
| 9 | 3974 | ipp | [‘M’, ‘iss’, ‘iss’, ‘ipp’, ‘il’, ‘ess’, ‘ly’] |
| 10 | 17140 | Poke away out | [‘Miss’, ‘iss’, ‘ipp’, ‘il’, ‘ess’, ‘ly’] |
| 11 | 30608 | iless | [‘Miss’, ‘iss’, ‘ipp’, ‘iless’, ‘ly’] |
On every step, the BPE algorithm finds the right pair of tokens to merge and merges them (you are going to be ready to glance the merged pair and its injurious within the output). This job brings down the token put dimension from Unicode’s 150k to 50k, and the choice of tokens (in this snort notice) from 17 to 5. Each are colossal improvements.
When working with a pair of phrases, the tokenizer first splits the textual bid material into separate phrases the utilization of this regexp and merges the tokens interior every notice individually. Sadly, PostgreSQL doesn’t beef up Unicode personality properties in regexps, so I had to tweak it a minute bit bit (presumably killing upright Unicode beef up within the job). This is how it appears to be like in SQL:
WITH input AS
(
SELECT 'PostgreSQL is colossal' AS suggested
),
clusters AS
(
SELECT part_position, bpe.FROM input
CROSS JOIN LATERAL
REGEXP_MATCHES(suggested, '''s|''t|''re|''ve|''m|''ll|''d| ?w+| ?d+| ?[^swd]+|s+(?!S)|s+', 'g') WITH ORDINALITY AS rm (portion, part_position)
CROSS JOIN LATERAL
(
WITH RECURSIVE
bpe AS
(
SELECT (n + 1)::BIGINT AS way, personality, TRUE AS proceed
FROM CONVERT_TO(portion[1], 'UTF-8') AS bytes
CROSS JOIN LATERAL
GENERATE_SERIES(0, LENGTH(bytes) - 1) AS n
JOIN encoder
ON byte = GET_BYTE(bytes, n)
UNION ALL
(
WITH RECURSIVE
bad AS
(
SELECT FROM bpe
WHERE proceed
),
bn AS
(
SELECT ROW_NUMBER() OVER (ORDER BY way) AS way,
proceed,
personality,
personality || LEAD(personality) OVER (ORDER BY way) AS cluster
FROM bad
),
top_rank AS
(
SELECT tokenizer.FROM bn
CROSS JOIN LATERAL
(
SELECT FROM tokenizer
WHERE tokenizer.cluster = bn.cluster
LIMIT 1
) tokenizer
ORDER BY
token
LIMIT 1
),
breaks AS
(
SELECT 0::BIGINT AS way, 1 AS dimension
UNION ALL
SELECT bn.way,
CASE WHEN token IS NULL THEN 1 ELSE 2 END
FROM breaks
JOIN bn
ON bn.way = breaks.way + dimension
LEFT JOIN
top_rank
USING (cluster)
)
SELECT way, personality, token IS NOT NULL
FROM breaks
LEFT JOIN
top_rank
ON 1 = 1
CROSS JOIN LATERAL
(
SELECT STRING_AGG(personality, '' ORDER BY way) AS personality
FROM bn
WHERE bn.way >= breaks.way
AND bn.way < breaks.position + length
) bn
WHERE position > 0
)
)
SELECT way, personality AS cluster
FROM bpe
WHERE NOT proceed
) bpe
),
tokens AS
(
SELECT token, cluster
FROM clusters
JOIN tokenizer
USING (cluster)
)
SELECT FROM tokens
| token | cluster |
|---|---|
| 6307 | Post |
| 47701 | greSQL |
| 318 | Ġis |
| 1049 | Ġgreat |
The irregular personality Ġ is the whitespace.
This ask tokenizes the suggested and converts it into an array of numbers. This form, the suggested is ready for its scamper thru the layers of the model.
Embeddings
The tokens signify parts of the human languages (about 0.75 phrases per token, in most cases), so any model that’s searching to be triumphant at textual bid material completion have to in a intention encode the relationships between these parts. Even in isolation, the parts of the speech procure sets of orthogonal properties.
Let’s hang the notice “subpoena” (which occurs to procure a entire token in itself within the GPT2 tokenizer). Is it a noun? Yes, very powerful so. Is it a verb? Properly, label of. Is it an adjective? No longer that powerful, nonetheless it no doubt will most likely be when you happen to squint arduous ample. Is it legalese? Hell yes. Etc.
All these properties are orthogonal, i.e. self sustaining of every pretty a pair of. A notice will most likely be a legalese noun nonetheless now not an adjective or a verb. In English, any aggregate thereof can happen.
Issues with orthogonal properties are superb encoded the utilization of vectors. As a substitute of getting a single property (adore a token number), we can procure many. And it helps if we can wiggle them as we need. As an illustration, for a notice to proceed the phrase “A courtroom resolution cited by the attorney mentions the …” we would presumably need something that’s heavy on the legalese dimension and at the identical time heavy on being a noun. We damage now not in actuality care if it has a facet hustle being an adjective, a verb, or a flower.
In math, mapping narrower values into wider areas (equivalent to token IDs to vectors) is named an embedding. This is precisely what we’re doing right here.
How can we take hang of which properties these vectors signify? We damage now not. We actual provide ample vector put for every token and hope that the model within the course of its training section will populate these dimensions with something meaningful. GPT2 uses 768 dimensions for its vectors. There could be now not any telling in attain (and, in actuality, even within the retrospective) what property of the notice will, teach, the dimension 247 encode. Completely it could presumably well encode something, nonetheless it no doubt’s now not easy to teach what it’s miles.
What properties of every token can we must embed within the vector put? Anything that has any relating what the following token would be.
Token id? Clearly. Diversified tokens indicate pretty a pair of things.
Station of the token within the textual bid material? Yes, please. “Blue violet” and “violet blue” are now not the identical component.
Relationships of tokens to every pretty a pair of? Sure! That’s, presumably, the superb portion of the job, and the Consideration block of the Transformer structure was the major one to get it appropriate.
Tokens and positions are easy to embed. Let’s assume now we procure the phrase “PostgreSQL is colossal”, which, as we already know, maps to four tokens: [6307, 47701, 318, 1049].
Among pretty a pair of parameters of GPT2, there are two matrixes known as WTE (notice token embedding) and WPE (notice way embedding). Because the names suggest, the ragged retail outlets embeddings of the tokens, and the latter retail outlets embeddings of the positions. The snort values of these embeddings had been populated (“discovered”) within the course of the studying of GPT2. As some distance as we’re concerned, they’re constants that reside within the database tables wte and wpe.
WTE is 50257×768 and WPE is 1024×768. The latter manner that the maximum decision of tokens that we can use in a suggested to GPT2 is 1024. If we provide extra tokens within the suggested, we actual could presumably well now not be ready to tug positional embeddings for them. It be an architectural component (“hyperparameter” in AI parlance) of the model that’s decided at create time and can’t be modified by training. When folks discuss the “context window” of an LLM, they indicate this number.
We now procure the token 6307 at web bid online 0, 47701 at 1, 318 at 2, and 1049 at 3. For every of these tokens and positions, now we procure two vectors: one from WTE and one other one from WPE. We now must add them together. The four resulting vectors stands out as the inputs for the following portion of the algorithm: the feed-forward neural network with the honor mechanism.
For the SQL portion, we can use pgvector, a PostgreSQL extension.
Fairly disclaimer: assuredly, I write code for my Contemporary Year posts in vanilla SQL, in most cases with pure SQL functions as helpers. It would be completely possible to enact it for this put up as well by defining vector operations on arrays, at the associated fee of some efficiency decrease (it was carried out in version 1 and labored, albeit slowly). With the creation of the AI and rising importance of vector databases, pgvector or its an identical will positively private it into the core of PostgreSQL within two or three releases. I actual decided to lope the wave of the long gallop.
This is how we enact that in SQL:
WITH embeddings AS
(
SELECT web bid online, values
FROM UNNEST(ARRAY[6307, 47701, 318, 1049]) WITH ORDINALITY AS tokens (token, ordinality)
CROSS JOIN LATERAL
(
SELECT ordinality - 1 AS web bid online
) o
CROSS JOIN LATERAL
(
SELECT wte.values + wpe.values AS values
FROM wte
CROSS JOIN
wpe
WHERE wte.token = tokens.token
AND wpe.web bid online = o.web bid online
) embedding
)
SELECT web bid online, (values::REAL[])[0:5]
FROM embeddings
| web bid online | values |
|---|---|
| 0 | [0.1035146, -0.22879261, 0.18413992, -0.29924694, 0.18642524] |
| 1 | [0.10757777, -0.0011023134, -0.0077463835, 0.03656415, -0.14654925] |
| 2 | [-0.005507436, -0.07471258, 0.11009377, -0.11708109, -0.14026159] |
| 3 | [-0.04785268, -0.0792546, 0.1628486, -0.3598496, 0.11462127] |
(To lend a hand the output rapid, this ask only presentations the major 5 dimensions for every vector)
Consideration
The portion that in actuality makes the Transformer structure tick is the self-consideration mechanism. It was first described within the 2017 paper “Consideration is all you’d like” by Vasmani et al., presumably the most eminent AI paper, whose name has since turn accurate into a snowclone (a cliché for naming pretty a pair of papers).
Up to now, now we procure lots of vectors that, confidently, encode some syntactic and semantic properties of the phrases in our suggested. We need these properties to in a intention switch to the final vector. Fairly spoiler alert: at the end of the day, this stands out as the final vector that can store the embedding for the continuation notice.
In a phrase adore “I checked out the violet and seen that it was now not the in trend …”, the ellipsis has to be something you glance (and this conception has to leap from “seen”), something that’s a property of a violet (leaping from “violet” to “it” after which to the ellipsis), and something that’s “uncommon” (leaping from “now not” and “in trend” and flipping the register the scale to blame for the usualness). The analogy within the right world would be an particular particular person studying a e-book in a foreign language that they variety of procure a in trend bid of, nonetheless damage now not pretty know totally. They’d must consciously heed their manner from one notice to one other, and if they damage now not hear to the wanted portion of the phrase, their working out would be imperfect.
To enable this switch of meaning from one token to one other, we must allow the vectors of all of the tokens to lead every pretty a pair of. If we must populate the notice “it” with some concrete semantics, how powerful of the semantics have to attain from the earlier vectors within the suggested, and the way in which powerful have to dwell from the notice “it” itself?
To solve this misfortune, the model uses 12 sets of matrixes known as Q (ask), K (key) and V (heed). Every of them has 64 columns. They are got from the vector embeddings thru a 768×2304 linear transformation c_attn, whose weights and biases are kept within the tables c_attn_w and c_attn_b.
The outcomes of c_attn is a matrix with n_token rows and 2304 columns (3×12×64). It consists of 12 Q matrixes, 12 K matrixes and 12 V matrixes stacked horizontally, in this expose.
Every location of Q, K and V is named a “head”. They are weak to label the step is named “multi-headed causal self-consideration”, by calculating the honor feature.
This is the system for the honor feature:
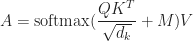
where softmax is the weight normalization feature. It be defined adore this:
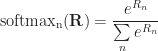
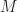
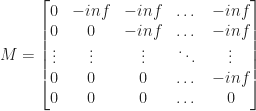
Softmax turns unfavorable infinities into zeros.
Why can we need masking?
The suggested in our earlier examples had 4 tokens, and the major component the model did was calculate the 4 embeddings for these 4 tokens. Because the model progresses, these vectors will undergo loads of calculations, nonetheless for the most portion, they’ll be self sustaining and parallel. Adjustments in a single vector will now not procure an influence on the pretty a pair of vectors, as if they had now not existed. The self-consideration block is the one web bid online within the entire model where the vectors procure an influence on every pretty a pair of.
Once the model is carried out with the math, the candidates for the following token will most likely be decided totally from the final embedding. Your entire data drift have to be directed in direction of this final vector and now not from it. The transient values of the final embedding have to now not procure an influence on the transient values of the earlier embeddings within the course of the forward trek of the model.
That’s why we “camouflage” the latter embeddings so that they damage now not influence the earlier embeddings thru this snort channel. Therefore the notice “causal” in “multi-headed causal self-consideration”.
Why are the matrixes known as “ask”, “key” and “heed”?
To be appropriate, I’m now not clear it’s even a honest analogy. But I will aloof enact my hang on the instinct behind it.
In machine studying, on the entire, calculations have to now not involve variable-dimension loops or observation branching. All the things have to be carried out thru the composition of easy analytic functions (additions, multiplications, powers, logarithms and trig). It enables backpropagation, which relies on technologies adore automatic differentiation, to work effectively.
The mathematical model of the most predominant-heed store is the expression
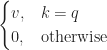
, nonetheless it no doubt’s now not a aloof, differentiable feature and this is in a position to presumably well now not work well with backpropagation. To private it work, we would must flip it accurate into a aloof feature that is at probability of be shut to 


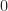
The Gaussian distribution (“bell curve”), scaled to

, where 
In a vector put with many ample dimensions, if we hang a mounted vector 
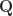
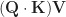
Over again, this analogy is powerful-fetched. It be superb now to now not pay too powerful consideration (no pun meant) to these concepts of consideration, meaning drift, hash tables etc. Upright deem of them as an inspiration for a math trick that has been put to the check and proved to work in actuality well.
Let’s illustrate this step:
WITH embeddings AS
(
SELECT web bid online, values
FROM UNNEST(ARRAY[6307, 47701, 318, 1049]) WITH ORDINALITY AS tokens (token, ordinality)
CROSS JOIN LATERAL
(
SELECT ordinality - 1 AS web bid online
) o
CROSS JOIN LATERAL
(
SELECT wte.values + wpe.values AS values
FROM wte
CROSS JOIN
wpe
WHERE wte.token = tokens.token
AND wpe.web bid online = o.web bid online
) embedding
),
c_attn_w AS
(
SELECT FROM c_attn_w
WHERE block = 0
),
c_attn_b AS
(
SELECT FROM c_attn_b
WHERE block = 0
),
ln_1_g AS
(
SELECT FROM ln_1_g
WHERE block = 0
),
ln_1_b AS
(
SELECT FROM ln_1_b
WHERE block = 0
),
mha_norm AS
(
SELECT web bid online, mm.values + c_attn_b.values AS values
FROM (
SELECT web bid online, ARRAY_AGG(INNER_PRODUCT(c_attn_w.values, layer_norm.values) ORDER BY y)::VECTOR(2304) AS values
FROM (
SELECT web bid online, agg.values ln_1_g.values + ln_1_b.values AS values
FROM (
SELECT web bid online, norm.values
FROM embeddings
CROSS JOIN LATERAL
(
SELECT AVG(heed) AS indicate,
VAR_POP(heed) AS variance
FROM UNNEST(values::REAL[]) heed
) agg
CROSS JOIN LATERAL
(
SELECT ARRAY_AGG((heed - indicate) / SQRT(variance + 1E-5) ORDER BY ordinality)::VECTOR(768) AS values
FROM UNNEST(values::REAL[]) WITH ORDINALITY AS n(heed, ordinality)
) norm
) agg
CROSS JOIN
ln_1_b
CROSS JOIN
ln_1_g
) layer_norm
CROSS JOIN
c_attn_w
GROUP BY
web bid online
) mm
CROSS JOIN
c_attn_b
),
head AS
(
SELECT web bid online,
(values::REAL[])[1: 64]::VECTOR(64) AS q,
(values::REAL[])[1 + 768: 64 + 768]::VECTOR(64) AS k,
(values::REAL[])[1 + 1536: 64 + 1536]::VECTOR(64) AS v
FROM mha_norm
),
sm_input AS
(
SELECT h1.web bid online AS x, h2.web bid online AS y, INNER_PRODUCT(h1.q, h2.k) / 8 + CASE WHEN h2.web bid online > h1.web bid online THEN -1E10 ELSE 0 END AS heed
FROM head h1
CROSS JOIN
head h2
),
sm_diff AS
(
SELECT x, y, heed - MAX(heed) OVER (PARTITION BY x) AS diff
FROM sm_input
),
sm_exp AS
(
SELECT x, y, CASE WHEN diff < -745.13 THEN 0 ELSE EXP(diff) END AS e
FROM sm_diff
),
softmax AS
(
SELECT x, y AS place, e / SUM(e) OVER (PARTITION BY x) AS value
FROM sm_exp
),
attention AS
(
SELECT place, (ARRAY_AGG(value ORDER BY ordinality))[:3] AS values
FROM (
SELECT x AS place, SUM(ARRAY_FILL(softmax.value, ARRAY[64])::VECTOR(64) head.v) AS values
FROM softmax
JOIN head
USING (place)
GROUP BY
x
) q
CROSS JOIN LATERAL
UNNEST(values::REAL[]) WITH ORDINALITY v (value, ordinality)
GROUP BY
place
)
SELECT place,
(SELECT STRING_AGG(TO_CHAR(n, 'S0.000'), ' ') || ' …' FROM UNNEST((q::REAL[])[:3]) AS n) AS q,
(SELECT STRING_AGG(TO_CHAR(n, 'S0.000'), ' ') || ' …' FROM UNNEST((k::REAL[])[:3]) AS n) AS k,
(SELECT STRING_AGG(TO_CHAR(n, 'S0.000'), ' ') || ' …' FROM UNNEST((v::REAL[])[:3]) AS n) AS v,
matrix,
(SELECT STRING_AGG(TO_CHAR(n, 'S0.000'), ' ') || ' …' FROM UNNEST((values::REAL[])[:3]) AS n) AS attention
FROM head
JOIN attention
USING (place)
JOIN (
SELECT x AS place, STRING_AGG(CASE WHEN value > 0 THEN TO_CHAR(heed, '0.00') ELSE ' 0' END, ' ' ORDER BY web bid online) AS matrix
FROM softmax
GROUP BY
x
) softmax_grouped
USING (web bid online)
| web bid online | q | k | v | matrix | consideration |
|---|---|---|---|---|---|
| 0 | +0.381 -0.579 +0.073 … | -1.395 +2.367 +0.332 … | -0.006 +0.192 +0.047 … | 1.00 0 0 0 | -0.006 +0.192 +0.047 … |
| 1 | +1.518 +0.827 -0.388 … | -2.380 +3.714 +0.659 … | -0.315 -0.062 +0.018 … | 0.73 0.27 0 0 | -0.089 +0.124 +0.039 … |
| 2 | +0.238 -0.226 +0.344 … | -1.952 +2.404 +1.953 … | +0.256 -0.268 +0.301 … | 0.67 0.26 0.07 0 | -0.069 +0.095 +0.057 … |
| 3 | +1.130 -0.011 -0.103 … | -2.855 +2.053 +2.813 … | +0.176 +0.019 -0.099 … | 0.59 0.19 0.12 0.10 | -0.016 +0.071 +0.058 … |
Right here is what we did:
- Sooner than calculating the honor feature, we normalized the vectors by making use of the linear transformation
. The matrix
and the vector
are known as “scale” and “shift”, accordingly. They are discovered parameters of the model, which are kept within the tables
ln_1_gandln_1_b - We’re only showing the major head of the major layer of the algorithm. After we multiplied the vectors by the discovered coefficients from
c_attn_wandc_attn_b(“weight” and “bias”), we sliced the resulting 2304-vectors, taking 64-vectors beginning at the positions 0, 768 and 1536. They correspond to the vectors Q, K and V for the major head. EXPin PostgreSQL fails on in actuality runt numbers, that’s why we shortcut to zero if the argument toEXPis much less than -745.13.- We’re only showing the major three parts for every vector. The honor matrix we demonstrate in chubby.
As we can glance, the major heed vector received copied to the output as is (as this is in a position to presumably well enact in every pretty a pair of layer of the algorithm). It manner that when the model has been trained, the output embedding for the major token will most likely be only defined by the associated fee of the major token. On the entire, within the course of the recursive inference section, where tokens only get added to the suggested, only the final embedding within the output will ever change when put next to the earlier iteration. This is what the causal camouflage does.
Having a stare a minute bit forward: the honor block is the only web bid online in all of the algorithm where tokens can influence every pretty a pair of within the course of the forward trek. Since now we procure disabled the flexibility of later tokens to lead the earlier ones in this step, all of the calculations carried out on the earlier tokens will most likely be reused between the forward passes of the model.
Be aware, the model operates by appending tokens to the suggested. If our normal (tokenized) suggested is “Post greSQL Ġis Ġgreat” and the following one will most likely be (for occasion) “Post greSQL Ġis Ġgreat Ġfor”, all of the implications of the calculations made on the major four tokens will most likely be reused for the new suggested; they could presumably well now not ever change, no topic what is appended to them.
Jay Mody’s illustrative article doesn’t private use of this truth (and neither can we, for the sake of simplicity), nonetheless the conventional GPT2 implementation does.
Once all of the heads are carried out, we can end up with 12 matrixes, every 64 columns extensive and n_tokens rows gigantic. To arrangement it abet to the dimension of embedding vectors (768), we actual must stack these matrixes horizontally.
The final step of multi-headed consideration involves projecting the values thru a discovered linear transformation of the identical dimension. Its weights and biases are kept within the tables c_proj_w and c_proj_b.
This is what the code for a entire multi-headed consideration step within the major layer appears to be like adore:
WITH embeddings AS
(
SELECT web bid online, values
FROM UNNEST(ARRAY[6307, 47701, 318, 1049]) WITH ORDINALITY AS tokens (token, ordinality)
CROSS JOIN LATERAL
(
SELECT ordinality - 1 AS web bid online
) o
CROSS JOIN LATERAL
(
SELECT wte.values + wpe.values AS values
FROM wte
CROSS JOIN
wpe
WHERE wte.token = tokens.token
AND wpe.web bid online = o.web bid online
) embedding
),
c_proj_w AS
(
SELECT FROM c_proj_w
WHERE block = 0
),
c_proj_b AS
(
SELECT FROM c_proj_b
WHERE block = 0
),
mlp_c_fc_w AS
(
SELECT FROM mlp_c_fc_w
WHERE block = 0
),
mlp_c_fc_b AS
(
SELECT FROM mlp_c_fc_b
WHERE block = 0
),
mlp_c_proj_w AS
(
SELECT FROM mlp_c_proj_w
WHERE block = 0
),
mlp_c_proj_b AS
(
SELECT FROM mlp_c_proj_b
WHERE block = 0
),
c_attn_w AS
(
SELECT FROM c_attn_w
WHERE block = 0
),
c_attn_b AS
(
SELECT FROM c_attn_b
WHERE block = 0
),
ln_1_g AS
(
SELECT FROM ln_1_g
WHERE block = 0
),
ln_1_b AS
(
SELECT FROM ln_1_b
WHERE block = 0
),
mha_norm AS
(
SELECT web bid online, mm.values + c_attn_b.values AS values
FROM (
SELECT web bid online, ARRAY_AGG(INNER_PRODUCT(c_attn_w.values, layer_norm.values) ORDER BY y)::VECTOR(2304) AS values
FROM (
SELECT web bid online, agg.values ln_1_g.values + ln_1_b.values AS values
FROM (
SELECT web bid online, norm.values
FROM embeddings
CROSS JOIN LATERAL
(
SELECT AVG(heed) AS indicate,
VAR_POP(heed) AS variance
FROM UNNEST(values::REAL[]) heed
) agg
CROSS JOIN LATERAL
(
SELECT ARRAY_AGG((heed - indicate) / SQRT(variance + 1E-5) ORDER BY ordinality)::VECTOR(768) AS values
FROM UNNEST(values::REAL[]) WITH ORDINALITY AS n(heed, ordinality)
) norm
) agg
CROSS JOIN
ln_1_b
CROSS JOIN
ln_1_g
) layer_norm
CROSS JOIN
c_attn_w
GROUP BY
web bid online
) mm
CROSS JOIN
c_attn_b
),
heads AS
(
SELECT web bid online, head,
(values::REAL[])[(head 64 + 1):(head 64 + 64)]::VECTOR(64) AS q,
(values::REAL[])[(head 64 + 1 + 768):(head 64 + 64 + 768)]::VECTOR(64) AS k,
(values::REAL[])[(head 64 + 1 + 1536):(head 64 + 64 + 1536)]::VECTOR(64) AS v
FROM mha_norm
CROSS JOIN
GENERATE_SERIES(0, 11) head
),
sm_input AS
(
SELECT head, h1.web bid online AS x, h2.web bid online AS y, INNER_PRODUCT(h1.q, h2.k) / 8 + CASE WHEN h2.web bid online > h1.web bid online THEN -1E10 ELSE 0 END AS heed
FROM heads h1
JOIN heads h2
USING (head)
),
sm_diff AS
(
SELECT head, x, y, heed - MAX(heed) OVER (PARTITION BY head, x) AS diff
FROM sm_input
),
sm_exp AS
(
SELECT head, x, y, CASE WHEN diff < -745.13 THEN 0 ELSE EXP(diff) END AS e
FROM sm_diff
),
softmax AS
(
SELECT head, x, y AS place, e / SUM(e) OVER (PARTITION BY head, x) AS value
FROM sm_exp
),
attention AS
(
SELECT place, ARRAY_AGG(value ORDER BY head 64 + ordinality)::VECTOR(768) AS values
FROM (
SELECT head, x AS place, SUM(ARRAY_FILL(softmax.value, ARRAY[64])::VECTOR(64) heads.v) AS values
FROM softmax
JOIN heads
USING (head, place)
GROUP BY
head, x
) q
CROSS JOIN LATERAL
UNNEST(values::REAL[]) WITH ORDINALITY v (value, ordinality)
GROUP BY
place
),
mha AS
(
SELECT place, w.values + c_proj_b.values AS values
FROM (
SELECT attention.place, ARRAY_AGG(INNER_PRODUCT(attention.values, c_proj_w.values) ORDER BY c_proj_w.place)::VECTOR(768) AS values
FROM attention
CROSS JOIN
c_proj_w
GROUP BY
attention.place
) w
CROSS JOIN
c_proj_b
)
SELECT place,
(SELECT STRING_AGG(TO_CHAR(n, 'S0.000'), ' ') || ' …' FROM UNNEST((values::REAL[])[: 10]) AS n) AS q
FROM mha
| place | q |
|---|---|
| 0 | +0.814 -1.407 +0.171 +0.008 +0.065 -0.049 -0.407 +1.178 -0.234 -0.061 … |
| 1 | +1.150 -0.430 +0.083 +0.030 +0.010 +0.015 -0.245 +3.778 -0.445 -0.004 … |
| 2 | -0.219 -0.745 -0.116 +0.032 +0.064 -0.044 +0.290 +3.187 -0.074 -0.003 … |
| 3 | -0.526 -0.757 -0.510 -0.008 +0.027 -0.017 +0.302 +2.842 +0.188 -0.028 … |
Before the results of multi-headed attention are passed to the next step, the original inputs are added to them. This trick was described in the original transformer paper. It's supposed to help with vanishing and exploding gradients.
It's a common problem during training: sometimes the gradients of the parameters turn out too big or too small. Changing them on the training iteration either has very little effect on the loss function (and so the model converges very slowly), or, on the opposite, has such a big effect that even a small change throws the loss function too far away from its local minimum, negating the training efforts.
Feedforward
This is what the deep neural networks do. The larger part of the model parameters is actually used at this step.
This step is a multi-layer perceptron with three layers (768, 3072, 768), using the Gaussian Error Linear Unit (GELU) as an activation function:


This function has been observed to yield good results in deep neural networks. It can be analytically approximated like this:
![mathrm{GELU}(x) displaystyle approx 0.5x left(1 + mathrm{tanh}left[0.797884left(x + 0.044715x^3right) right]right)](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BGELU%7D%28x%29+%5Cdisplaystyle+%5Capprox+0.5x+%5Cleft%281+%2B+%5Cmathrm%7Btanh%7D%5Cleft%5B0.797884%5Cleft%28x+%2B+0.044715x%5E3%5Cright%29+%5Cright%5D%5Cright%29+&bg=fff&fg=1c1c1c&s=0&c=20201002)
The learned linear transformation parameters for layer connections are called c_fc (768 → 3072) and c_proj (3072 → 768). The values for the first layer are first normalized using the coefficients in the learned parameter ln_2. After the feedforward step is completed, its input is again added to the output. This, too, is a part of the original transformer design.
The whole feedforward step looks like this:

And here's how we do this in SQL:
WITH embeddings AS
(
SELECT place, values
FROM UNNEST(ARRAY[6307, 47701, 318, 1049]) WITH ORDINALITY AS tokens (token, ordinality)
CROSS JOIN LATERAL
(
SELECT ordinality - 1 AS place
) o
CROSS JOIN LATERAL
(
SELECT wte.values + wpe.values AS values
FROM wte
CROSS JOIN
wpe
WHERE wte.token = tokens.token
AND wpe.place = o.place
) embedding
),
c_proj_w AS
(
SELECT FROM c_proj_w
WHERE block = 0
),
c_proj_b AS
(
SELECT FROM c_proj_b
WHERE block = 0
),
mlp_c_fc_w AS
(
SELECT FROM mlp_c_fc_w
WHERE block = 0
),
mlp_c_fc_b AS
(
SELECT FROM mlp_c_fc_b
WHERE block = 0
),
mlp_c_proj_w AS
(
SELECT FROM mlp_c_proj_w
WHERE block = 0
),
mlp_c_proj_b AS
(
SELECT FROM mlp_c_proj_b
WHERE block = 0
),
c_attn_w AS
(
SELECT FROM c_attn_w
WHERE block = 0
),
c_attn_b AS
(
SELECT FROM c_attn_b
WHERE block = 0
),
ln_1_g AS
(
SELECT FROM ln_1_g
WHERE block = 0
),
ln_1_b AS
(
SELECT FROM ln_1_b
WHERE block = 0
),
ln_2_b AS
(
SELECT FROM ln_2_b
WHERE block = 0
),
ln_2_g AS
(
SELECT FROM ln_2_g
WHERE block = 0
),
mha_norm AS
(
SELECT place, mm.values + c_attn_b.values AS values
FROM (
SELECT place, ARRAY_AGG(INNER_PRODUCT(c_attn_w.values, layer_norm.values) ORDER BY y)::VECTOR(2304) AS values
FROM (
SELECT place, agg.values ln_1_g.values + ln_1_b.values AS values
FROM (
SELECT place, norm.values
FROM embeddings
CROSS JOIN LATERAL
(
SELECT AVG(value) AS mean,
VAR_POP(value) AS variance
FROM UNNEST(values::REAL[]) value
) agg
CROSS JOIN LATERAL
(
SELECT ARRAY_AGG((value - mean) / SQRT(variance + 1E-5) ORDER BY ordinality)::VECTOR(768) AS values
FROM UNNEST(values::REAL[]) WITH ORDINALITY AS n(value, ordinality)
) norm
) agg
CROSS JOIN
ln_1_b
CROSS JOIN
ln_1_g
) layer_norm
CROSS JOIN
c_attn_w
GROUP BY
place
) mm
CROSS JOIN
c_attn_b
),
heads AS
(
SELECT place, head,
(values::REAL[])[(head 64 + 1):(head 64 + 64)]::VECTOR(64) AS q,
(values::REAL[])[(head 64 + 1 + 768):(head 64 + 64 + 768)]::VECTOR(64) AS k,
(values::REAL[])[(head 64 + 1 + 1536):(head 64 + 64 + 1536)]::VECTOR(64) AS v
FROM mha_norm
CROSS JOIN
GENERATE_SERIES(0, 11) head
),
sm_input AS
(
SELECT head, h1.place AS x, h2.place AS y, INNER_PRODUCT(h1.q, h2.k) / 8 + CASE WHEN h2.place > h1.web bid online THEN -1E10 ELSE 0 END AS heed
FROM heads h1
JOIN heads h2
USING (head)
),
sm_diff AS
(
SELECT head, x, y, heed - MAX(heed) OVER (PARTITION BY head, x) AS diff
FROM sm_input
),
sm_exp AS
(
SELECT head, x, y, CASE WHEN diff < -745.13 THEN 0 ELSE EXP(diff) END AS e
FROM sm_diff
),
softmax AS
(
SELECT head, x, y AS place, e / SUM(e) OVER (PARTITION BY head, x) AS value
FROM sm_exp
),
attention AS
(
SELECT place, ARRAY_AGG(value ORDER BY head 64 + ordinality)::VECTOR(768) AS values
FROM (
SELECT head, x AS place, SUM(ARRAY_FILL(softmax.value, ARRAY[64])::VECTOR(64) heads.v) AS values
FROM softmax
JOIN heads
USING (head, place)
GROUP BY
head, x
) q
CROSS JOIN LATERAL
UNNEST(values::REAL[]) WITH ORDINALITY v (value, ordinality)
GROUP BY
place
),
mha AS
(
SELECT place, w.values + c_proj_b.values + embeddings.values AS values
FROM (
SELECT attention.place, ARRAY_AGG(INNER_PRODUCT(attention.values, c_proj_w.values) ORDER BY c_proj_w.place)::VECTOR(768) AS values
FROM attention
CROSS JOIN
c_proj_w
GROUP BY
attention.place
) w
CROSS JOIN
c_proj_b
JOIN embeddings
USING (place)
),
ffn_norm AS
(
SELECT place, agg.values ln_2_g.values + ln_2_b.values AS values
FROM (
SELECT place, norm.values
FROM mha
CROSS JOIN LATERAL
(
SELECT AVG(value) AS mean,
VAR_POP(value) AS variance
FROM UNNEST(values::REAL[]) value
) agg
CROSS JOIN LATERAL
(
SELECT ARRAY_AGG((value - mean) / SQRT(variance + 1E-5) ORDER BY ordinality)::VECTOR(768) AS values
FROM UNNEST(values::REAL[]) WITH ORDINALITY AS n(value, ordinality)
) norm
) agg
CROSS JOIN
ln_2_b
CROSS JOIN
ln_2_g
),
ffn_a AS
(
SELECT gelu.place, gelu.values
FROM (
SELECT place, w.values + mlp_c_fc_b.values AS values
FROM (
SELECT ffn_norm.place, ARRAY_AGG(INNER_PRODUCT(ffn_norm.values, mlp_c_fc_w.values) ORDER BY mlp_c_fc_w.place)::VECTOR(3072) AS values
FROM ffn_norm
CROSS JOIN
mlp_c_fc_w
GROUP BY
ffn_norm.place
) w
CROSS JOIN
mlp_c_fc_b
) v
CROSS JOIN LATERAL
(
SELECT place, ARRAY_AGG(0.5 value (1 + TANH(0.797884560802 (value + 0.044715 value*value*value))) ORDER BY ordinality)::VECTOR(3072) AS values
FROM UNNEST(values::REAL[]) WITH ORDINALITY n (value, ordinality)
GROUP BY
place
) gelu
),
ffn AS
(
SELECT place, w.values + mlp_c_proj_b.values + mha.values AS values
FROM (
SELECT ffn_a.place, ARRAY_AGG(INNER_PRODUCT(ffn_a.values, mlp_c_proj_w.values) ORDER BY mlp_c_proj_w.place)::VECTOR(768) AS values
FROM ffn_a
CROSS JOIN
mlp_c_proj_w
GROUP BY
ffn_a.place
) w
CROSS JOIN
mlp_c_proj_b
JOIN mha
USING (place)
)
SELECT place,
(SELECT STRING_AGG(TO_CHAR(n, 'S0.000'), ' ') || ' …' FROM UNNEST((values::REAL[])[: 10]) AS n) AS q
FROM ffn
| place | q |
|---|---|
| 0 | +0.309 -1.267 -0.250 -1.111 -0.226 +0.549 -0.346 +0.645 -1.603 -0.501 … |
| 1 | +0.841 -1.081 +0.227 -1.029 -1.554 +1.061 -0.070 +5.258 -1.892 -0.973 … |
| 2 | -1.256 -0.528 -0.846 -0.288 +0.166 +0.409 +0.019 +3.393 +0.085 -0.212 … |
| 3 | -1.007 -1.719 -0.725 -1.417 -0.086 -0.144 +0.605 +3.272 +1.051 -0.666 … |
This output is what comes out of the first block of GPT2.
Blocks
What we saw in the previous steps is repeated in layers (called "blocks"). The blocks are set up in a pipeline so that the output of a previous block goes straight to the next one. Each block has its own set of learned parameters.
In SQL, we would need to connect the blocks using a recursive CTE.
Once the final block produces the values, we need to normalize it using the learned parameter ln_f.
Here's what the model ultimately looks like:

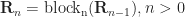
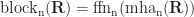
![displaystyle mathbf R_0 = mathrm{wte}(tokens) + mathrm{wpe}([1 ldots mathrm{dim}(tokens)])](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbf+R_0+%3D+%5Cmathrm%7Bwte%7D%28tokens%29+%2B+%5Cmathrm%7Bwpe%7D%28%5B1+%5Cldots+%5Cmathrm%7Bdim%7D%28tokens%29%5D%29&bg=fff&fg=1c1c1c&s=0&c=20201002)
And that is how it appears to be like in SQL:
WITH RECURSIVE
initial AS
(
SELECT ARRAY[6307, 47701, 318, 1049] AS input
),
hparams AS
(
SELECT 12 AS n_block
),
embeddings AS
(
SELECT web bid online, values
FROM initial
CROSS JOIN
hparams
CROSS JOIN LATERAL
UNNEST(input) WITH ORDINALITY AS tokens (token, ordinality)
CROSS JOIN LATERAL
(
SELECT ordinality - 1 AS web bid online
) o
CROSS JOIN LATERAL
(
SELECT wte.values + wpe.values AS values
FROM wte
CROSS JOIN
wpe
WHERE wte.token = tokens.token
AND wpe.web bid online = o.web bid online
) embedding
),
turn into AS
(
SELECT 0 AS block, web bid online, values
FROM embeddings
UNION ALL
(
WITH earlier AS
(
SELECT FROM turn into
)
SELECT block + 1 AS block, transformed_layer.FROM hparams
CROSS JOIN LATERAL
(
SELECT block
FROM earlier
WHERE block < 12
LIMIT 1
) q
CROSS JOIN LATERAL
(
WITH ln_2_b AS
(
SELECT FROM ln_2_b
WHERE block = q.block
),
ln_2_g AS
(
SELECT FROM ln_2_g
WHERE block = q.block
),
c_proj_w AS
(
SELECT FROM c_proj_w
WHERE block = q.block
),
c_proj_b AS
(
SELECT FROM c_proj_b
WHERE block = q.block
),
mlp_c_fc_w AS
(
SELECT FROM mlp_c_fc_w
WHERE block = q.block
),
mlp_c_fc_b AS
(
SELECT FROM mlp_c_fc_b
WHERE block = q.block
),
mlp_c_proj_w AS
(
SELECT FROM mlp_c_proj_w
WHERE block = q.block
),
mlp_c_proj_b AS
(
SELECT FROM mlp_c_proj_b
WHERE block = q.block
),
c_attn_w AS
(
SELECT FROM c_attn_w
WHERE block = q.block
),
c_attn_b AS
(
SELECT FROM c_attn_b
WHERE block = q.block
),
ln_1_g AS
(
SELECT FROM ln_1_g
WHERE block = q.block
),
ln_1_b AS
(
SELECT FROM ln_1_b
WHERE block = q.block
),
mha_norm AS
(
SELECT place, mm.values + c_attn_b.values AS values
FROM (
SELECT place, ARRAY_AGG(INNER_PRODUCT(c_attn_w.values, layer_norm.values) ORDER BY y)::VECTOR(2304) AS values
FROM (
SELECT place, agg.values ln_1_g.values + ln_1_b.values AS values
FROM (
SELECT place, norm.values
FROM previous
CROSS JOIN LATERAL
(
SELECT AVG(value) AS mean,
VAR_POP(value) AS variance
FROM UNNEST(values::REAL[]) value
) agg
CROSS JOIN LATERAL
(
SELECT ARRAY_AGG((value - mean) / SQRT(variance + 1E-5) ORDER BY ordinality)::VECTOR(768) AS values
FROM UNNEST(values::REAL[]) WITH ORDINALITY AS n(value, ordinality)
) norm
) agg
CROSS JOIN
ln_1_b
CROSS JOIN
ln_1_g
) layer_norm
CROSS JOIN
c_attn_w
GROUP BY
place
) mm
CROSS JOIN
c_attn_b
),
heads AS
(
SELECT place, head,
(values::REAL[])[(head 64 + 1):(head 64 + 64)]::VECTOR(64) AS q,
(values::REAL[])[(head 64 + 1 + 768):(head 64 + 64 + 768)]::VECTOR(64) AS k,
(values::REAL[])[(head 64 + 1 + 1536):(head 64 + 64 + 1536)]::VECTOR(64) AS v
FROM mha_norm
CROSS JOIN
GENERATE_SERIES(0, 11) head
),
sm_input AS
(
SELECT head, h1.place AS x, h2.place AS y, INNER_PRODUCT(h1.q, h2.k) / 8 + CASE WHEN h2.place > h1.web bid online THEN -1E10 ELSE 0 END AS heed
FROM heads h1
JOIN heads h2
USING (head)
),
sm_diff AS
(
SELECT head, x, y, heed - MAX(heed) OVER (PARTITION BY head, x) AS diff
FROM sm_input
),
sm_exp AS
(
SELECT head, x, y, CASE WHEN diff < -745.13 THEN 0 ELSE EXP(diff) END AS e
FROM sm_diff
),
softmax AS
(
SELECT head, x, y AS web bid online, e / SUM(e) OVER (PARTITION BY head, x) AS heed
FROM sm_exp
),
consideration AS
(
SELECT web bid online, ARRAY_AGG(heed ORDER BY head 64 + ordinality)::VECTOR(768) AS values
FROM (
SELECT head, x AS web bid online, SUM(ARRAY_FILL(softmax.heed, ARRAY[64])::VECTOR(64) heads.v) AS values
FROM softmax
JOIN heads
USING (head, web bid online)
GROUP BY
head, x
) q
CROSS JOIN LATERAL
UNNEST(values::REAL[]) WITH ORDINALITY v (heed, ordinality)
GROUP BY
web bid online
),
mha AS
(
SELECT web bid online, w.values + c_proj_b.values + earlier.values AS values
FROM (
SELECT consideration.web bid online, ARRAY_AGG(INNER_PRODUCT(consideration.values, c_proj_w.values) ORDER BY c_proj_w.web bid online)::VECTOR(768) AS values
FROM consideration
CROSS JOIN
c_proj_w
GROUP BY
consideration.web bid online
) w
CROSS JOIN
c_proj_b
JOIN earlier
USING (web bid online)
),
ffn_norm AS
(
SELECT web bid online, agg.values ln_2_g.values + ln_2_b.values AS values
FROM (
SELECT web bid online, norm.values
FROM mha
CROSS JOIN LATERAL
(
SELECT AVG(heed) AS indicate,
VAR_POP(heed) AS variance
FROM UNNEST(values::REAL[]) heed
) agg
CROSS JOIN LATERAL
(
SELECT ARRAY_AGG((heed - indicate) / SQRT(variance + 1E-5) ORDER BY ordinality)::VECTOR(768) AS values
FROM UNNEST(values::REAL[]) WITH ORDINALITY AS n(heed, ordinality)
) norm
) agg
CROSS JOIN
ln_2_b
CROSS JOIN
ln_2_g
),
ffn_a AS
(
SELECT gelu.web bid online, gelu.values
FROM (
SELECT web bid online, w.values + mlp_c_fc_b.values AS values
FROM (
SELECT ffn_norm.web bid online, ARRAY_AGG(INNER_PRODUCT(ffn_norm.values, mlp_c_fc_w.values) ORDER BY mlp_c_fc_w.web bid online)::VECTOR(3072) AS values
FROM ffn_norm
CROSS JOIN
mlp_c_fc_w
GROUP BY
ffn_norm.web bid online
) w
CROSS JOIN
mlp_c_fc_b
) v
CROSS JOIN LATERAL
(
SELECT web bid online, ARRAY_AGG(0.5 heed (1 + TANH(0.797884560802 (heed + 0.044715 heed*heed*heed))) ORDER BY ordinality)::VECTOR(3072) AS values
FROM UNNEST(values::REAL[]) WITH ORDINALITY n (heed, ordinality)
GROUP BY
web bid online
) gelu
),
ffn AS
(
SELECT web bid online, w.values + mlp_c_proj_b.values + mha.values AS values
FROM (
SELECT ffn_a.web bid online, ARRAY_AGG(INNER_PRODUCT(ffn_a.values, mlp_c_proj_w.values) ORDER BY mlp_c_proj_w.web bid online)::VECTOR(768) AS values
FROM ffn_a
CROSS JOIN
mlp_c_proj_w
GROUP BY
ffn_a.web bid online
) w
CROSS JOIN
mlp_c_proj_b
JOIN mha
USING (web bid online)
)
SELECT FROM ffn
) transformed_layer
)
),
block_output AS
(
SELECT FROM hparams
JOIN turn into
ON turn into.block = n_block
),
ln_f AS
(
SELECT web bid online, norm.values ln_f_g.values + ln_f_b.values AS values
FROM block_output
CROSS JOIN LATERAL
(
SELECT AVG(heed) AS indicate,
VAR_POP(heed) AS variance
FROM UNNEST(values::REAL[]) AS n(heed)
) agg
CROSS JOIN LATERAL
(
SELECT ARRAY_AGG((heed - indicate) / SQRT(variance + 1E-5) ORDER BY ordinality)::VECTOR(768) AS values
FROM UNNEST(values::REAL[]) WITH ORDINALITY AS n (heed, ordinality)
) norm
CROSS JOIN
ln_f_b
CROSS JOIN
ln_f_g
)
SELECT web bid online,
(SELECT STRING_AGG(TO_CHAR(n, 'S0.000'), ' ') || ' …' FROM UNNEST((values::REAL[])[: 10]) AS n) AS q
FROM ln_f
| web bid online | q |
|---|---|
| 0 | -0.153 -0.126 -0.368 +0.028 -0.013 -0.198 +0.661 +0.056 -0.228 -0.001 … |
| 1 | -0.157 -0.314 +0.291 -0.386 -0.273 -0.054 +3.397 +0.440 -0.137 -0.243 … |
| 2 | -0.912 -0.220 -0.886 -0.661 +0.491 -0.050 +0.693 +1.128 +0.031 -0.577 … |
| 3 | -0.098 -0.323 -1.479 -0.736 +0.235 -0.608 +1.774 +0.566 -0.057 -0.211 … |
This is the output of the model.
The fourth vector is the right embedding of the following token predicted by the model. We actual must arrangement it abet to the tokens.
Tokens
We now procure an embedding (a 768-vector) which, in keeping with the model, captures the semantics and the grammar of the most likely continuation of the suggested. Now we must arrangement it abet to the token.
One among the major steps the model makes is mapping the tokens to their embeddings. It is carried out thru the 50257×768 matrix wpe. We will most likely be in a position to must use the identical matrix to arrangement the embedding abet to the token.
The misfortune is that the right reverse mapping is now not possible: the embedding will now not (most likely) be equal to any of the rows within the matrix. So we can must procure the "closest" token to the embedding.
Since the scale of embeddings bewitch (as we hope) some semantic and grammatical aspects of the token, we need them to match as carefully as possible. One manner to consolidate the closeness of every dimension would be to actual calculate the dot comprised of the 2 embeddings. The larger the dot product, the nearer the token is to the prediction.
To enact this, we can multiply the embedding by the matrix wte. The consequence will most likely be a single-column matrix, 50257 rows gigantic. Every heed in this consequence stands out as the dot comprised of the predicted embedding and the token embedding. The larger this number, the extra most likely it's miles for the token to proceed the suggested.
To hang the following token, we can must convert the similarities to possibilities. To enact this, we can use our honest pal softmax (the identical feature that we weak to normalize consideration weights).
Why use softmax for possibilities?
Softmax has the good property of fulfilling Luce's decision axiom. It manner that the relative possibilities of two choices damage now not rely on the presence or probability of pretty a pair of choices. If A is twice as possible as B, then the presence or absence of pretty a pair of choices will now not change this ratio (even though it undoubtedly can change the absolute values).
The vector of dot products ("logit" in AI parlance) contains arbitrary ratings that damage now not procure an intrinsic scale. If A has a bigger gain than B, we know that it's extra most likely, nonetheless that's about it. We are in a position to tweak the inputs to softmax as we please, as long as they lend a hand their expose (i.e. bigger ratings stop bigger).
One in trend manner to enact that's to normalize the ratings by subtracting the superb heed from the location from them (in relate that the superb gain turns into 0 and the relaxation turn into unfavorable numbers). Then we hang some mounted number (for instance 5 or ten) high ratings. In the shatter, we multiply every gain by a constant earlier than feeding it to softmax.
The decision of high ratings that we hang is incessantly known as 

The system for tokens' possibilities is 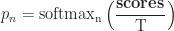
Why is it known as "temperature"?
The softmax feature has one other name: Boltzmann distribution. It be widely weak in physics. Among pretty a pair of things, it serves as a foul for the barometric system, which tells how density or air varies with altitude.
Intuitively, sizzling air rises. It spreads extra some distance from the Earth. When air is sizzling, it's extra most likely for an air molecule to leap off its neighbors and jump at an otherwise very unlikely height. When put next to colder temperatures, air density increases at bigger altitudes and drops at sea stage.
See how air behaves at pretty a pair of temperatures:
Courtesy of Dominic Ford, Bouncing Balls and the Boltzmann Distribution
By analogy, a immense "temperature" increases the probability of second-decision tokens being selected (at the expense of the major-decision tokens, undoubtedly). The inference turns into much less predictable and extra "artistic".
Let's put this all into SQL. The suggested was "PostgreSQL is colossal". Right here are the shatter 5 tokens that, in keeping with the model, are most likely to proceed this phrase, and their possibilities at pretty a pair of temperatures:
WITH RECURSIVE
initial AS
(
SELECT ARRAY[6307, 47701, 318, 1049] AS input
),
hparams AS
(
SELECT 12 AS n_block,
5 AS top_n,
ARRAY_LENGTH(input, 1) AS n_seq
FROM initial
),
embeddings AS
(
SELECT web bid online, values
FROM initial
CROSS JOIN
hparams
CROSS JOIN LATERAL
UNNEST(input) WITH ORDINALITY AS tokens (token, ordinality)
CROSS JOIN LATERAL
(
SELECT ordinality - 1 AS web bid online
) o
CROSS JOIN LATERAL
(
SELECT wte.values + wpe.values AS values
FROM wte
CROSS JOIN
wpe
WHERE wte.token = tokens.token
AND wpe.web bid online = o.web bid online
) embedding
),
turn into AS
(
SELECT 0 AS block, web bid online, values
FROM embeddings
UNION ALL
(
WITH earlier AS
(
SELECT FROM turn into
)
SELECT block + 1 AS block, transformed_layer.FROM hparams
CROSS JOIN LATERAL
(
SELECT block
FROM earlier
WHERE block < 12
LIMIT 1
) q
CROSS JOIN LATERAL
(
WITH ln_2_b AS
(
SELECT FROM ln_2_b
WHERE block = q.block
),
ln_2_g AS
(
SELECT FROM ln_2_g
WHERE block = q.block
),
c_proj_w AS
(
SELECT FROM c_proj_w
WHERE block = q.block
),
c_proj_b AS
(
SELECT FROM c_proj_b
WHERE block = q.block
),
mlp_c_fc_w AS
(
SELECT FROM mlp_c_fc_w
WHERE block = q.block
),
mlp_c_fc_b AS
(
SELECT FROM mlp_c_fc_b
WHERE block = q.block
),
mlp_c_proj_w AS
(
SELECT FROM mlp_c_proj_w
WHERE block = q.block
),
mlp_c_proj_b AS
(
SELECT FROM mlp_c_proj_b
WHERE block = q.block
),
c_attn_w AS
(
SELECT FROM c_attn_w
WHERE block = q.block
),
c_attn_b AS
(
SELECT FROM c_attn_b
WHERE block = q.block
),
ln_1_g AS
(
SELECT FROM ln_1_g
WHERE block = q.block
),
ln_1_b AS
(
SELECT FROM ln_1_b
WHERE block = q.block
),
mha_norm AS
(
SELECT place, mm.values + c_attn_b.values AS values
FROM (
SELECT place, ARRAY_AGG(INNER_PRODUCT(c_attn_w.values, layer_norm.values) ORDER BY y)::VECTOR(2304) AS values
FROM (
SELECT place, agg.values ln_1_g.values + ln_1_b.values AS values
FROM (
SELECT place, norm.values
FROM previous
CROSS JOIN LATERAL
(
SELECT AVG(value) AS mean,
VAR_POP(value) AS variance
FROM UNNEST(values::REAL[]) value
) agg
CROSS JOIN LATERAL
(
SELECT ARRAY_AGG((value - mean) / SQRT(variance + 1E-5) ORDER BY ordinality)::VECTOR(768) AS values
FROM UNNEST(values::REAL[]) WITH ORDINALITY AS n(value, ordinality)
) norm
) agg
CROSS JOIN
ln_1_b
CROSS JOIN
ln_1_g
) layer_norm
CROSS JOIN
c_attn_w
GROUP BY
place
) mm
CROSS JOIN
c_attn_b
),
heads AS
(
SELECT place, head,
(values::REAL[])[(head 64 + 1):(head 64 + 64)]::VECTOR(64) AS q,
(values::REAL[])[(head 64 + 1 + 768):(head 64 + 64 + 768)]::VECTOR(64) AS k,
(values::REAL[])[(head 64 + 1 + 1536):(head 64 + 64 + 1536)]::VECTOR(64) AS v
FROM mha_norm
CROSS JOIN
GENERATE_SERIES(0, 11) head
),
sm_input AS
(
SELECT head, h1.place AS x, h2.place AS y, INNER_PRODUCT(h1.q, h2.k) / 8 + CASE WHEN h2.place > h1.web bid online THEN -1E10 ELSE 0 END AS heed
FROM heads h1
JOIN heads h2
USING (head)
),
sm_diff AS
(
SELECT head, x, y, heed - MAX(heed) OVER (PARTITION BY head, x) AS diff
FROM sm_input
),
sm_exp AS
(
SELECT head, x, y, CASE WHEN diff < -745.13 THEN 0 ELSE EXP(diff) END AS e
FROM sm_diff
),
softmax AS
(
SELECT head, x, y AS web bid online, e / SUM(e) OVER (PARTITION BY head, x) AS heed
FROM sm_exp
),
consideration AS
(
SELECT web bid online, ARRAY_AGG(heed ORDER BY head 64 + ordinality)::VECTOR(768) AS values
FROM (
SELECT head, x AS web bid online, SUM(ARRAY_FILL(softmax.heed, ARRAY[64])::VECTOR(64) heads.v) AS values
FROM softmax
JOIN heads
USING (head, web bid online)
GROUP BY
head, x
) q
CROSS JOIN LATERAL
UNNEST(values::REAL[]) WITH ORDINALITY v (heed, ordinality)
GROUP BY
web bid online
),
mha AS
(
SELECT web bid online, w.values + c_proj_b.values + earlier.values AS values
FROM (
SELECT consideration.web bid online, ARRAY_AGG(INNER_PRODUCT(consideration.values, c_proj_w.values) ORDER BY c_proj_w.web bid online)::VECTOR(768) AS values
FROM consideration
CROSS JOIN
c_proj_w
GROUP BY
consideration.web bid online
) w
CROSS JOIN
c_proj_b
JOIN earlier
USING (web bid online)
),
ffn_norm AS
(
SELECT web bid online, agg.values ln_2_g.values + ln_2_b.values AS values
FROM (
SELECT web bid online, norm.values
FROM mha
CROSS JOIN LATERAL
(
SELECT AVG(heed) AS indicate,
VAR_POP(heed) AS variance
FROM UNNEST(values::REAL[]) heed
) agg
CROSS JOIN LATERAL
(
SELECT ARRAY_AGG((heed - indicate) / SQRT(variance + 1E-5) ORDER BY ordinality)::VECTOR(768) AS values
FROM UNNEST(values::REAL[]) WITH ORDINALITY AS n(heed, ordinality)
) norm
) agg
CROSS JOIN
ln_2_b
CROSS JOIN
ln_2_g
),
ffn_a AS
(
SELECT gelu.web bid online, gelu.values
FROM (
SELECT web bid online, w.values + mlp_c_fc_b.values AS values
FROM (
SELECT ffn_norm.web bid online, ARRAY_AGG(INNER_PRODUCT(ffn_norm.values, mlp_c_fc_w.values) ORDER BY mlp_c_fc_w.web bid online)::VECTOR(3072) AS values
FROM ffn_norm
CROSS JOIN
mlp_c_fc_w
GROUP BY
ffn_norm.web bid online
) w
CROSS JOIN
mlp_c_fc_b
) v
CROSS JOIN LATERAL
(
SELECT web bid online, ARRAY_AGG(0.5 heed (1 + TANH(0.797884560802 (heed + 0.044715 heed*heed*heed))) ORDER BY ordinality)::VECTOR(3072) AS values
FROM UNNEST(values::REAL[]) WITH ORDINALITY n (heed, ordinality)
GROUP BY
web bid online
) gelu
),
ffn AS
(
SELECT web bid online, w.values + mlp_c_proj_b.values + mha.values AS values
FROM (
SELECT ffn_a.web bid online, ARRAY_AGG(INNER_PRODUCT(ffn_a.values, mlp_c_proj_w.values) ORDER BY mlp_c_proj_w.web bid online)::VECTOR(768) AS values
FROM ffn_a
CROSS JOIN
mlp_c_proj_w
GROUP BY
ffn_a.web bid online
) w
CROSS JOIN
mlp_c_proj_b
JOIN mha
USING (web bid online)
)
SELECT FROM ffn
) transformed_layer
)
),
block_output AS
(
SELECT FROM hparams
JOIN turn into
ON turn into.block = n_block
),
ln_f AS
(
SELECT web bid online, norm.values ln_f_g.values + ln_f_b.values AS values
FROM block_output
CROSS JOIN LATERAL
(
SELECT AVG(heed) AS indicate,
VAR_POP(heed) AS variance
FROM UNNEST(values::REAL[]) AS n(heed)
) agg
CROSS JOIN LATERAL
(
SELECT ARRAY_AGG((heed - indicate) / SQRT(variance + 1E-5) ORDER BY ordinality)::VECTOR(768) AS values
FROM UNNEST(values::REAL[]) WITH ORDINALITY AS n (heed, ordinality)
) norm
CROSS JOIN
ln_f_b
CROSS JOIN
ln_f_g
),
logits AS
(
SELECT logits.FROM hparams
CROSS JOIN LATERAL
(
SELECT token, INNER_PRODUCT(ln_f.values, wte.values) AS heed
FROM ln_f
CROSS JOIN
wte
WHERE ln_f.web bid online = n_seq - 1
ORDER BY
heed DESC
LIMIT (top_n)
) logits
),
temperatures (temperature) AS
(
VALUES
(0.5),
(1),
(2)
),
tokens AS
(
SELECT token, heed, softmax, temperature
FROM temperatures
CROSS JOIN LATERAL
(
SELECT *, (e / SUM(e) OVER ()) AS softmax
FROM (
SELECT *,
(heed - MAX(heed) OVER ()) / temperature AS diff
FROM logits
) exp_x
CROSS JOIN LATERAL
(
SELECT CASE WHEN diff < -745.13 THEN 0 ELSE EXP(diff) END AS e
) exp
) q
)
SELECT token,
cluster,
TO_CHAR(t1.value, 'S00.000') AS score,
TO_CHAR(t1.softmax, '0.00') AS "temperature = 0.5",
TO_CHAR(t2.softmax, '0.00') AS "temperature = 1",
TO_CHAR(t3.softmax, '0.00') AS "temperature = 2"
FROM (
SELECT FROM tokens
WHERE temperature = 0.5
) t1
JOIN (
SELECT FROM tokens
WHERE temperature = 1
) t2
USING (token)
JOIN (
SELECT FROM tokens
WHERE temperature = 2
) t3
USING (token)
JOIN tokenizer
USING (token)
| token | cluster | score | temperature = 0.5 | temperature = 1 | temperature = 2 |
|---|---|---|---|---|---|
| 329 | Ġfor | -85.435 | 0.74 | 0.48 | 0.33 |
| 11 | , | -86.232 | 0.15 | 0.22 | 0.22 |
| 13 | . | -86.734 | 0.05 | 0.13 | 0.17 |
| 379 | Ġat | -86.785 | 0.05 | 0.12 | 0.17 |
| 284 | Ġto | -87.628 | 0.01 | 0.05 | 0.11 |
Inference
Finally, we are ready to do some real inference: run the model, select a token according to its probability, add it to the prompt and repeat until enough tokens are generated.
The LLM itself, as we saw before, is deterministic: it's just a series of matrix multiplications and other math operations on predefined constants. As long as the prompt and the hyperparameters like temperature and top_n are the same, the output will also be the same.
The only non-deterministic process is token selection. There is randomness involved in it (to a variable degree). That's why GPT-based chatbots can give different answers to the same prompt.
We will use the phrase "Happy New Year! I wish" as the prompt and make the model generate 10 new tokens for this prompt. The temperature will be set to 2, and top_n will be set to 5.
The query runs for 2: 44 minutes on my machine. Here's its output:
SELECT SETSEED(0.20231231);
WITH RECURSIVE
input AS
(
SELECT 'Happy New Year! I wish you' AS prompt,
10 AS threshold,
2 AS temperature,
1 AS top_n
),
clusters AS
(
SELECT part_position, bpe.FROM input
CROSS JOIN LATERAL
REGEXP_MATCHES(prompt, '''s|''t|''re|''ve|''m|''ll|''d| ?w+| ?d+| ?[^swd]+|s+(?!S)|s+', 'g') WITH ORDINALITY AS rm (part, part_position)
CROSS JOIN LATERAL
(
WITH RECURSIVE
bpe AS
(
SELECT (n + 1)::BIGINT AS position, character, TRUE AS continue
FROM CONVERT_TO(part[1], 'UTF-8') AS bytes
CROSS JOIN LATERAL
GENERATE_SERIES(0, LENGTH(bytes) - 1) AS n
JOIN encoder
ON byte = GET_BYTE(bytes, n)
UNION ALL
(
WITH RECURSIVE
base AS
(
SELECT FROM bpe
WHERE continue
),
bn AS
(
SELECT ROW_NUMBER() OVER (ORDER BY position) AS position,
continue,
character,
character || LEAD(character) OVER (ORDER BY position) AS cluster
FROM base
),
top_rank AS
(
SELECT tokenizer.FROM bn
CROSS JOIN LATERAL
(
SELECT FROM tokenizer
WHERE tokenizer.cluster = bn.cluster
LIMIT 1
) tokenizer
ORDER BY
token
LIMIT 1
),
breaks AS
(
SELECT 0::BIGINT AS position, 1 AS length
UNION ALL
SELECT bn.position,
CASE WHEN token IS NULL THEN 1 ELSE 2 END
FROM breaks
JOIN bn
ON bn.position = breaks.position + length
LEFT JOIN
top_rank
USING (cluster)
)
SELECT position, character, token IS NOT NULL
FROM breaks
LEFT JOIN
top_rank
ON 1 = 1
CROSS JOIN LATERAL
(
SELECT STRING_AGG(character, '' ORDER BY position) AS character
FROM bn
WHERE bn.position >= breaks.way
AND bn.way < breaks.position + length
) bn
WHERE position > 0
)
)
SELECT way, personality AS cluster
FROM bpe
WHERE NOT proceed
) bpe
),
tokens AS
(
SELECT ARRAY_AGG(token ORDER BY part_position, way) AS input
FROM clusters
JOIN tokenizer
USING (cluster)
),
gpt AS
(
SELECT input, ARRAY_LENGTH(input, 1) AS original_length
FROM tokens
UNION ALL
SELECT input || next_token.token, original_length
FROM gpt
CROSS JOIN
input
CROSS JOIN LATERAL
(
WITH RECURSIVE
hparams AS
(
SELECT ARRAY_LENGTH(input, 1) AS n_seq,
12 AS n_block
),
embeddings AS
(
SELECT web bid online, values
FROM hparams
CROSS JOIN LATERAL
UNNEST(input) WITH ORDINALITY AS tokens (token, ordinality)
CROSS JOIN LATERAL
(
SELECT ordinality - 1 AS web bid online
) o
CROSS JOIN LATERAL
(
SELECT wte.values + wpe.values AS values
FROM wte
CROSS JOIN
wpe
WHERE wte.token = tokens.token
AND wpe.web bid online = o.web bid online
) embedding
),
turn into AS
(
SELECT 0 AS block, web bid online, values
FROM embeddings
UNION ALL
(
WITH earlier AS
(
SELECT FROM turn into
)
SELECT block + 1 AS block, transformed_layer.FROM hparams
CROSS JOIN LATERAL
(
SELECT block
FROM earlier
WHERE block < 12
LIMIT 1
) q
CROSS JOIN LATERAL
(
WITH ln_2_b AS
(
SELECT FROM ln_2_b
WHERE block = q.block
),
ln_2_g AS
(
SELECT FROM ln_2_g
WHERE block = q.block
),
c_proj_w AS
(
SELECT FROM c_proj_w
WHERE block = q.block
),
c_proj_b AS
(
SELECT FROM c_proj_b
WHERE block = q.block
),
mlp_c_fc_w AS
(
SELECT FROM mlp_c_fc_w
WHERE block = q.block
),
mlp_c_fc_b AS
(
SELECT FROM mlp_c_fc_b
WHERE block = q.block
),
mlp_c_proj_w AS
(
SELECT FROM mlp_c_proj_w
WHERE block = q.block
),
mlp_c_proj_b AS
(
SELECT FROM mlp_c_proj_b
WHERE block = q.block
),
c_attn_w AS
(
SELECT FROM c_attn_w
WHERE block = q.block
),
c_attn_b AS
(
SELECT FROM c_attn_b
WHERE block = q.block
),
ln_1_g AS
(
SELECT FROM ln_1_g
WHERE block = q.block
),
ln_1_b AS
(
SELECT FROM ln_1_b
WHERE block = q.block
),
mha_norm AS
(
SELECT place, mm.values + c_attn_b.values AS values
FROM (
SELECT place, ARRAY_AGG(INNER_PRODUCT(c_attn_w.values, layer_norm.values) ORDER BY y)::VECTOR(2304) AS values
FROM (
SELECT place, agg.values ln_1_g.values + ln_1_b.values AS values
FROM (
SELECT place, norm.values
FROM previous
CROSS JOIN LATERAL
(
SELECT AVG(value) AS mean,
VAR_POP(value) AS variance
FROM UNNEST(values::REAL[]) value
) agg
CROSS JOIN LATERAL
(
SELECT ARRAY_AGG((value - mean) / SQRT(variance + 1E-5) ORDER BY ordinality)::VECTOR(768) AS values
FROM UNNEST(values::REAL[]) WITH ORDINALITY AS n(value, ordinality)
) norm
) agg
CROSS JOIN
ln_1_b
CROSS JOIN
ln_1_g
) layer_norm
CROSS JOIN
c_attn_w
GROUP BY
place
) mm
CROSS JOIN
c_attn_b
),
heads AS
(
SELECT place, head,
(values::REAL[])[(head 64 + 1):(head 64 + 64)]::VECTOR(64) AS q,
(values::REAL[])[(head 64 + 1 + 768):(head 64 + 64 + 768)]::VECTOR(64) AS k,
(values::REAL[])[(head 64 + 1 + 1536):(head 64 + 64 + 1536)]::VECTOR(64) AS v
FROM mha_norm
CROSS JOIN
GENERATE_SERIES(0, 11) head
),
sm_input AS
(
SELECT head, h1.place AS x, h2.place AS y, INNER_PRODUCT(h1.q, h2.k) / 8 + CASE WHEN h2.place > h1.web bid online THEN -1E10 ELSE 0 END AS heed
FROM heads h1
JOIN heads h2
USING (head)
),
sm_diff AS
(
SELECT head, x, y, heed - MAX(heed) OVER (PARTITION BY head, x) AS diff
FROM sm_input
),
sm_exp AS
(
SELECT head, x, y, CASE WHEN diff < -745.13 THEN 0 ELSE EXP(diff) END AS e
FROM sm_diff
),
softmax AS
(
SELECT head, x, y AS web bid online, e / SUM(e) OVER (PARTITION BY head, x) AS heed
FROM sm_exp
),
consideration AS
(
SELECT web bid online, ARRAY_AGG(heed ORDER BY head 64 + ordinality)::VECTOR(768) AS values
FROM (
SELECT head, x AS web bid online, SUM(ARRAY_FILL(softmax.heed, ARRAY[64])::VECTOR(64) heads.v) AS values
FROM softmax
JOIN heads
USING (head, web bid online)
GROUP BY
head, x
) q
CROSS JOIN LATERAL
UNNEST(values::REAL[]) WITH ORDINALITY v (heed, ordinality)
GROUP BY
web bid online
),
mha AS
(
SELECT web bid online, w.values + c_proj_b.values + earlier.values AS values
FROM (
SELECT consideration.web bid online, ARRAY_AGG(INNER_PRODUCT(consideration.values, c_proj_w.values) ORDER BY c_proj_w.web bid online)::VECTOR(768) AS values
FROM consideration
CROSS JOIN
c_proj_w
GROUP BY
consideration.web bid online
) w
CROSS JOIN
c_proj_b
JOIN earlier
USING (web bid online)
),
ffn_norm AS
(
SELECT web bid online, agg.values ln_2_g.values + ln_2_b.values AS values
FROM (
SELECT web bid online, norm.values
FROM mha
CROSS JOIN LATERAL
(
SELECT AVG(heed) AS indicate,
VAR_POP(heed) AS variance
FROM UNNEST(values::REAL[]) heed
) agg
CROSS JOIN LATERAL
(
SELECT ARRAY_AGG((heed - indicate) / SQRT(variance + 1E-5) ORDER BY ordinality)::VECTOR(768) AS values
FROM UNNEST(values::REAL[]) WITH ORDINALITY AS n(heed, ordinality)
) norm
) agg
CROSS JOIN
ln_2_b
CROSS JOIN
ln_2_g
),
ffn_a AS
(
SELECT gelu.web bid online, gelu.values
FROM (
SELECT web bid online, w.values + mlp_c_fc_b.values AS values
FROM (
SELECT ffn_norm.web bid online, ARRAY_AGG(INNER_PRODUCT(ffn_norm.values, mlp_c_fc_w.values) ORDER BY mlp_c_fc_w.web bid online)::VECTOR(3072) AS values
FROM ffn_norm
CROSS JOIN
mlp_c_fc_w
GROUP BY
ffn_norm.web bid online
) w
CROSS JOIN
mlp_c_fc_b
) v
CROSS JOIN LATERAL
(
SELECT web bid online, ARRAY_AGG(0.5 heed (1 + TANH(0.797884560802 (heed + 0.044715 heed*heed*heed))) ORDER BY ordinality)::VECTOR(3072) AS values
FROM UNNEST(values::REAL[]) WITH ORDINALITY n (heed, ordinality)
GROUP BY
web bid online
) gelu
),
ffn AS
(
SELECT web bid online, w.values + mlp_c_proj_b.values + mha.values AS values
FROM (
SELECT ffn_a.web bid online, ARRAY_AGG(INNER_PRODUCT(ffn_a.values, mlp_c_proj_w.values) ORDER BY mlp_c_proj_w.web bid online)::VECTOR(768) AS values
FROM ffn_a
CROSS JOIN
mlp_c_proj_w
GROUP BY
ffn_a.web bid online
) w
CROSS JOIN
mlp_c_proj_b
JOIN mha
USING (web bid online)
)
SELECT FROM ffn
) transformed_layer
)
),
block_output AS
(
SELECT FROM hparams
JOIN turn into
ON turn into.block = n_block
),
ln_f AS
(
SELECT web bid online, norm.values ln_f_g.values + ln_f_b.values AS values
FROM block_output
CROSS JOIN LATERAL
(
SELECT AVG(heed) AS indicate,
VAR_POP(heed) AS variance
FROM UNNEST(values::REAL[]) AS n(heed)
) agg
CROSS JOIN LATERAL
(
SELECT ARRAY_AGG((heed - indicate) / SQRT(variance + 1E-5) ORDER BY ordinality)::VECTOR(768) AS values
FROM UNNEST(values::REAL[]) WITH ORDINALITY AS n (heed, ordinality)
) norm
CROSS JOIN
ln_f_b
CROSS JOIN
ln_f_g
),
logits AS
(
SELECT token, INNER_PRODUCT(ln_f.values, wte.values) AS heed
FROM hparams
JOIN ln_f
ON ln_f.web bid online = n_seq - 1
CROSS JOIN
wte
ORDER BY
heed DESC
LIMIT (top_n)
),
tokens AS
(
SELECT token,
excessive - softmax AS low,
excessive
FROM (
SELECT *,
SUM(softmax) OVER (ORDER BY softmax) AS excessive
FROM (
SELECT *, (e / SUM(e) OVER ()) AS softmax
FROM (
SELECT *,
(heed - MAX(heed) OVER ()) / temperature AS diff
FROM logits
) exp_x
CROSS JOIN LATERAL
(
SELECT CASE WHEN diff < -745.13 THEN 0 ELSE EXP(diff) END AS e
) exp
) q
) q
),
next_token AS
(
SELECT FROM (
SELECT RANDOM() AS rnd
) r
CROSS JOIN LATERAL
(
SELECT FROM tokens
WHERE rnd >= low
AND rnd < excessive
) nt
)
SELECT FROM next_token
) next_token
WHERE ARRAY_LENGTH(input, 1) < original_length + threshold
AND next_token.token <> 50256
),
output AS
(
SELECT CONVERT_FROM(STRING_AGG(SET_BYTE('x00', 0, byte), '' ORDER BY way), 'UTF8') AS response
FROM (
SELECT STRING_AGG(cluster, '' ORDER BY ordinality) AS response
FROM input
JOIN gpt
ON ARRAY_LENGTH(input, 1) = original_length + threshold
CROSS JOIN LATERAL
UNNEST(input) WITH ORDINALITY n (token, ordinality)
JOIN tokenizer
USING (token)
) q
CROSS JOIN LATERAL
STRING_TO_TABLE(response, NULL) WITH ORDINALITY n (personality, way)
JOIN encoder
USING (personality)
)
SELECT FROM output
| response |
|---|
| Overjoyed Contemporary Year! I wish you all of the right in your new 365 days! |
This portion the AI received appropriate. I enact wish you all of the right in your new 365 days!
It's possible you'll presumably well procure the queries and the installation code within the GitHub repository: quassnoi/interpret-extended-2024
Overjoyed Contemporary Year!
Outdated Contemporary Year posts:
- 2010: SQL graphics in Oracle, MySQL, SQL Server and PostgreSQL
- 2011: Drawing a clock in SQL
- 2012: Drawing snowflakes in SQL
- 2013: Glimpse of Earth from put in SQL
- 2014: Drawing fractals in SQL
- 2015: Composing tune in SQL
- 2016: Conway’s Sport of Life in SQL
- 2017: The Sultan’s Riddle in SQL
- 2018: Settlers of Catan in SQL
- 2019: GIF decoder in SQL
- 2020: A stereogram in SQL
- 2021: 3D image of the coronavirus in SQL
- 2022: Quantum computer emulator in SQL
- 2023: Solving the Rubik’s Dice in SQL