The One Billion Row Divulge of affairs in Plod: from 1m45s to 4s in 9 solutions
March 2024
Plod to: Baseline | Solutions | Table of outcomes | Closing feedback
I saw the One Billion Row Divulge of affairs a couple of weeks previously, and it totally nerd-sniped me, so I went to Plod resolve it.
I’m slack to the occasion, as the long-established competition used to be in January. It used to be also in Java. I’m not namely in Java, but I’ve been in optimising Plod code for a while.
This self-discipline used to be namely easy: direction of a text file of weather set names and temperatures, and for each weather set, print out the minimum, point out, and most. There are just a few other constraints to construct it extra rapid-witted, though I unnoticed the Java-explicit ones.
Listed below are just a few strains of example enter:
Hamburg;12.0
Bulawayo;8.9
Palembang;38.8
St. John's;15.2
Cracow;12.6
...
The finest explain: the enter file has a billion rows (strains). That’s about 13GB of records. I’ve already figured out that disk I/O will not be any longer the bottleneck – it’s in general reminiscence allocations and parsing that behind things down in a program fancy this.
This article describes the 9 solutions I wrote in Plod, each faster than the old. The first, a easy and idiomatic resolution, runs in 1 minute 45 seconds on my machine, while the last one runs in about 4 seconds. As I lope, I’ll sign how I worn Plod’s profiler to leer where the time used to be being spent.
The gallop-down of solutions is as follows, slowest to fastest:
- r1: easy and idiomatic
- r2: plan with pointer values
- r3: parse temperatures by hand
- r4: mounted level integers
- r5: steer sure of
bytes.Minimize - r6: steer sure of
bufio.Scanner - r7: personalized hash desk
- r8: parallelise r1
- r9: parallelise r7
I needed each of the solutions to be portable Plod the explain of easiest the bizarre library: no assembly, no unsafe, and no reminiscence-mapped files. And 4 seconds, or 3.2GB/s, used to be snappy sufficient for me. For comparison, the fastest, carefully-optimised Java resolution runs in precisely below a 2nd on my machine – not substandard!
There are several other Plod solutions accessible already, and on the very least one good write-up. Mine is sooner than some solutions, but slightly slower than the fastest one. Alternatively, I didn’t seek for at any of these ahead of writing mine – I needed my solutions to be self sufficient.
Must you appropriate care about the numbers, skip down to the desk of outcomes.
Baseline
Listed below are just a few assorted baseline measurements to space the stage. First, how lengthy does it take to appropriate learn 13GB of records, the explain of cat:
$ time cat measurements.txt >/dev/null
0m1.052s
Explain that that’s a easiest-of-five dimension, so I’m allowing the file to be cached. Who’s aware of whether Linux will allow all 13GB to be kept in disk cache, though presumably it does, because the first time it took closer to 6 seconds.
For comparison, to surely attain something with the file is significantly slower: wc takes nearly a minute:
$ time wc measurements.txt
1000000000 1179173106 13795293380 measurements.txt
0m55.710s
For a easy resolution to the actual self-discipline, I’d doubtlessly initiate with AWK. This resolution uses Stare, because sorting the output is much less complex with its asorti operate. I’m the explain of the -b solution to explain “characters as bytes” mode, which makes things slightly faster:
$ time imprint -b -f 1brc.awk measurements.txt >measurements.out
7m35.567s
I’m sure I will beat 7 minutes with even a easy Plod resolution, so let’s initiate there.
I’m going to initiate by optimising the sequential, single-core model (solutions 1-7), and then parallelise it (solutions 8 and 9). All my outcomes are done the explain of Plod 1.21.5 on a linux/amd64 notebook computer with a rapid SSD pressure and 32GB of RAM.
Many of my solutions, and diverse the fastest solutions, rob real enter. As an illustration, that the temperatures admire precisely one decimal digit. A few of my solutions will cause a runtime dismay, or produce fallacious output, if the enter isn’t real.
Acknowledge 1: easy and idiomatic Plod
I needed my first model to be easy, straight-forward code the explain of the instruments in the Plod bizarre library: bufio.Scanner to learn the strains, strings.Minimize to split on the ';', strconv.ParseFloat to parse the temperatures, and an bizarre Plod plan to acquire the outcomes.
I’ll consist of this first resolution in fleshy (but after that, sign easiest the provocative bits):
func r1(inputPath string, output io.Creator) error {
model stats struct {
min, max, sum waft64
count int64
}
f, err := os.Open(inputPath)
if err != nil {
return err
}
defer f.Conclude()
stationStats := construct(plan[string]stats)
scanner := bufio.NewScanner(f)
for scanner.Scan() {
line := scanner.Text()
set, tempStr, hasSemi := strings.Minimize(line, ";")
if !hasSemi {
continue
}
temp, err := strconv.ParseFloat(tempStr, 64)
if err != nil {
return err
}
s, ok := stationStats[station]
if !ok {
s.min = temp
s.max = temp
s.sum = temp
s.count = 1
} else {
s.min = min(s.min, temp)
s.max = max(s.max, temp)
s.sum += temp
s.count++
}
stationStats[station] = s
}
stations := construct([]string, 0, len(stationStats))
for set := fluctuate stationStats {
stations = append(stations, set)
}
kind.Strings(stations)
fmt.Fprint(output, "{")
for i, set := fluctuate stations {
if i > 0 {
fmt.Fprint(output, ", ")
}
s := stationStats[station]
point out := s.sum / waft64(s.count)
fmt.Fprintf(output, "%s=%.1f/%.1f/%.1f", set, s.min, point out, s.max)
}
fmt.Fprint(output, "}n")
return nil
}
This bizarre resolution processes the a billion rows in 1 minute and 45 seconds. A particular enchancment over 7 minutes for the AWK resolution.
Acknowledge 2: plan with pointer values
I’d realized doing my count-phrases program that we’re doing a bunch extra hashing than now we favor to. For each line, we’re hashing the string twice: as soon as as soon as we strive to fetch the tag from the plan, and as soon as as soon as we update the plan.
To steer sure of that, we can explain a plan[string]*stats (pointer values) and update the pointed-to struct, in favor to a plan[string]stats and updating the hash desk itself.
Alternatively, I first wished to verify that the explain of the Plod profiler. It easiest takes a few strains to add CPU profiling to a Plod program.
$ ./lope-1brc -cpuprofile=cpu.prof -revision=1 measurements-10000000.txt >measurements-10000000.out
Processed 131.6MB in 965.888929ms
$ lope tool pprof -http=: cpu.prof
...
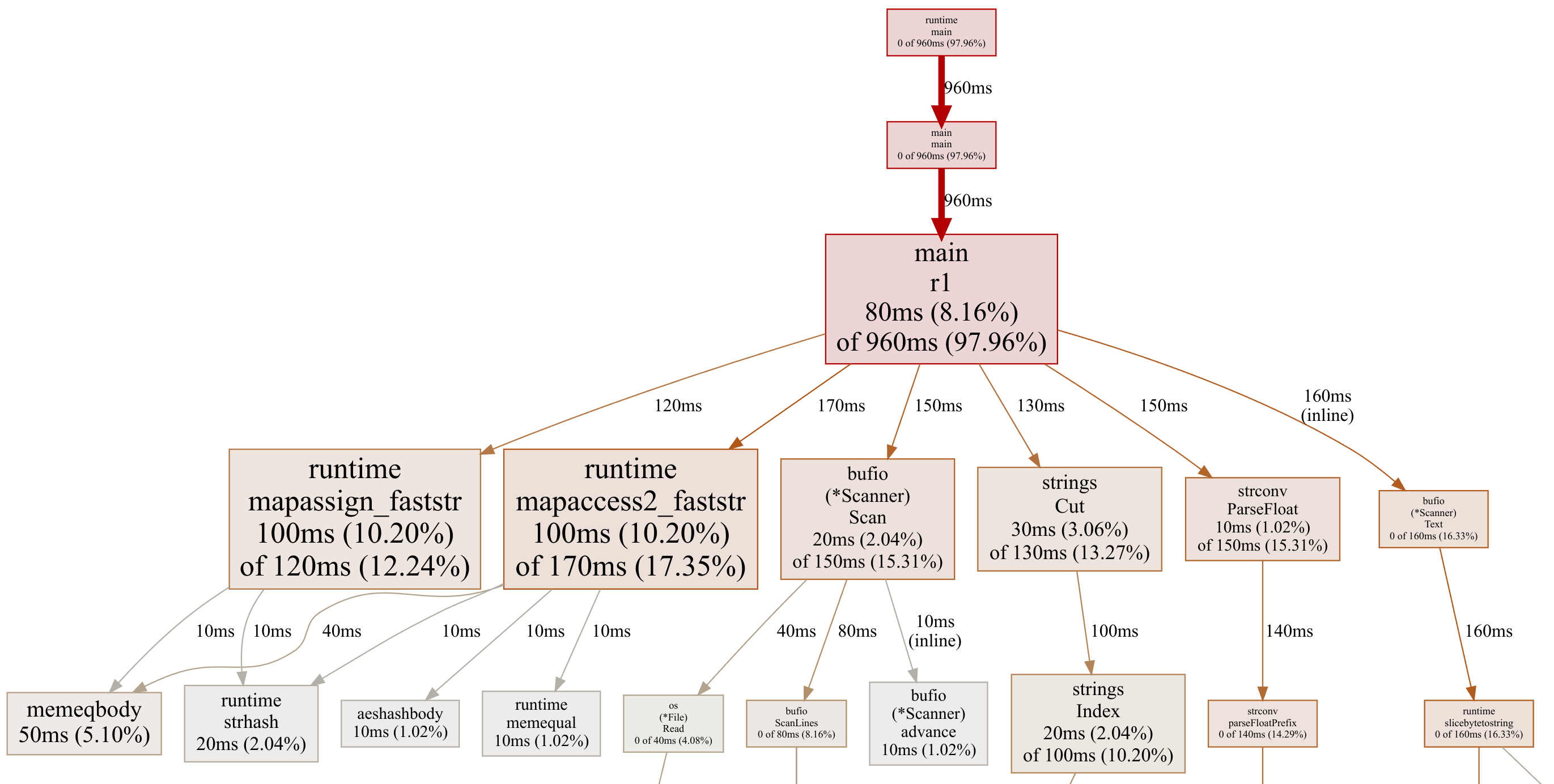
These commands produced the following profile of resolution 1, gallop over a slash-down 10 million row enter file:
Plan operations are taking a fleshy 30% of the time: 12.24% for set and 17.35% for lookup. We have to aloof have the skill to find rid of many of the plan set time by the explain of a pointer tag.
As a aspect existing, this profile image also reveals us where the total leisure of the time is going:
- Scanning strains with
Scanner.Scan - Finding the
';'withstrings.Minimize - Parsing the temperature with
strconv.ParseFloat - Calling
Scanner.Text, which allocates a string for the line
At the least, my 2nd resolution is appropriate a little tweak to the plan operations:
stationStats := construct(plan[string]*stats)
scanner := bufio.NewScanner(f)
for scanner.Scan() {
// ...
s := stationStats[station]
if s == nil {
stationStats[station] = &stats{
min: temp,
max: temp,
sum: temp,
count: 1,
}
} else {
s.min = min(s.min, temp)
s.max = max(s.max, temp)
s.sum += temp
s.count++
}
}
In the frequent case where the set exists in the plan, we now easiest attain one plan operation, s := stationStats[station], so that hashing the set name and accessing the hash desk easiest have to be done as soon as. If it’s in the plan already – the frequent case in a billion rows – we update the present pointed-to struct.
It doesn’t abet a ton, but it is something: the explain of pointer values in the plan takes our time down from 1 minute 45 seconds to 1 minute 31 seconds.
Acknowledge 3: steer sure of strconv.ParseFloat
My third resolution is where things find slightly extra exhausting-core: parse the temperature the explain of personalized code in favor to strconv.ParseFloat. The bizarre library operate handles a ton of edge cases we don’t have to red meat up for the easy temperatures our enter has: 2 or 3 digits in the structure 1.2 or 34.5 (and a few with a minus register entrance).
Also, strconv.ParseFloat took a string argument, and now that we’re not calling that, we can find away with the explain of the byte slash straight from Scanner.Bytes, in favor to allocating and copying a string with Scanner.Text.
Now we parse the temperature this methodology:
harmful := unfounded
index := 0
if tempBytes[index] == '-' {
index++
harmful = factual
}
temp := waft64(tempBytes[index] - '0') // parse first digit
index++
if tempBytes[index] != '.' {
temp = temp*10 + waft64(tempBytes[index]-'0') // parse optional 2nd digit
index++
}
index++ // skip '.'
temp += waft64(tempBytes[index]-'0') / 10 // parse decimal digit
if harmful {
temp = -temp
}
No longer rather, but not precisely rocket science both. This will get our time down from to 1 minute 31 seconds to below a minute: 55.8 seconds.
Acknowledge 4: mounted level integers
Lend a hand in the olden days, floating level directions had been a lot slower than integer ones. At the present time, they’re easiest a cramped slower, but it’s doubtlessly price averting them if we can.
For this self-discipline, each temperature has a single decimal digit, so it’s easy to explain mounted level integers to exclaim them. As an illustration, we can screech 34.5 as the integer 345. Then on the stay, appropriate ahead of we print out the outcomes, we convert them assist to floats.
So my fourth resolution is admittedly akin to resolution 3, but with the stats struct arena as follows:
model stats struct {
min, max, count int32
sum int64
}
Then, when printing out the outcomes, now we favor to divide by 10:
point out := waft64(s.sum) / waft64(s.count) / 10
fmt.Fprintf(output, "%s=%.1f/%.1f/%.1f",
set, waft64(s.min)/10, point out, waft64(s.max)/10)
I’ve worn 32-bit integers for minimum and most temperatures, as the finest we’ll doubtlessly admire is ready 500 (50 levels Celsius). Shall we explain int16, but from old trip, contemporary 64-bit CPUs are slightly slower when handling 16-bit integers than 32-bit ones. In my assessments appropriate now it didn’t appear to construct a measurable distinction, but I opted for 32-bit anyway.
The explain of integers slash the time down from 55.8 seconds to 51.0 seconds, a little acquire.
Acknowledge 5: steer sure of bytes.Minimize
To construct resolution 5 I recorded one other profile (of resolution 4):
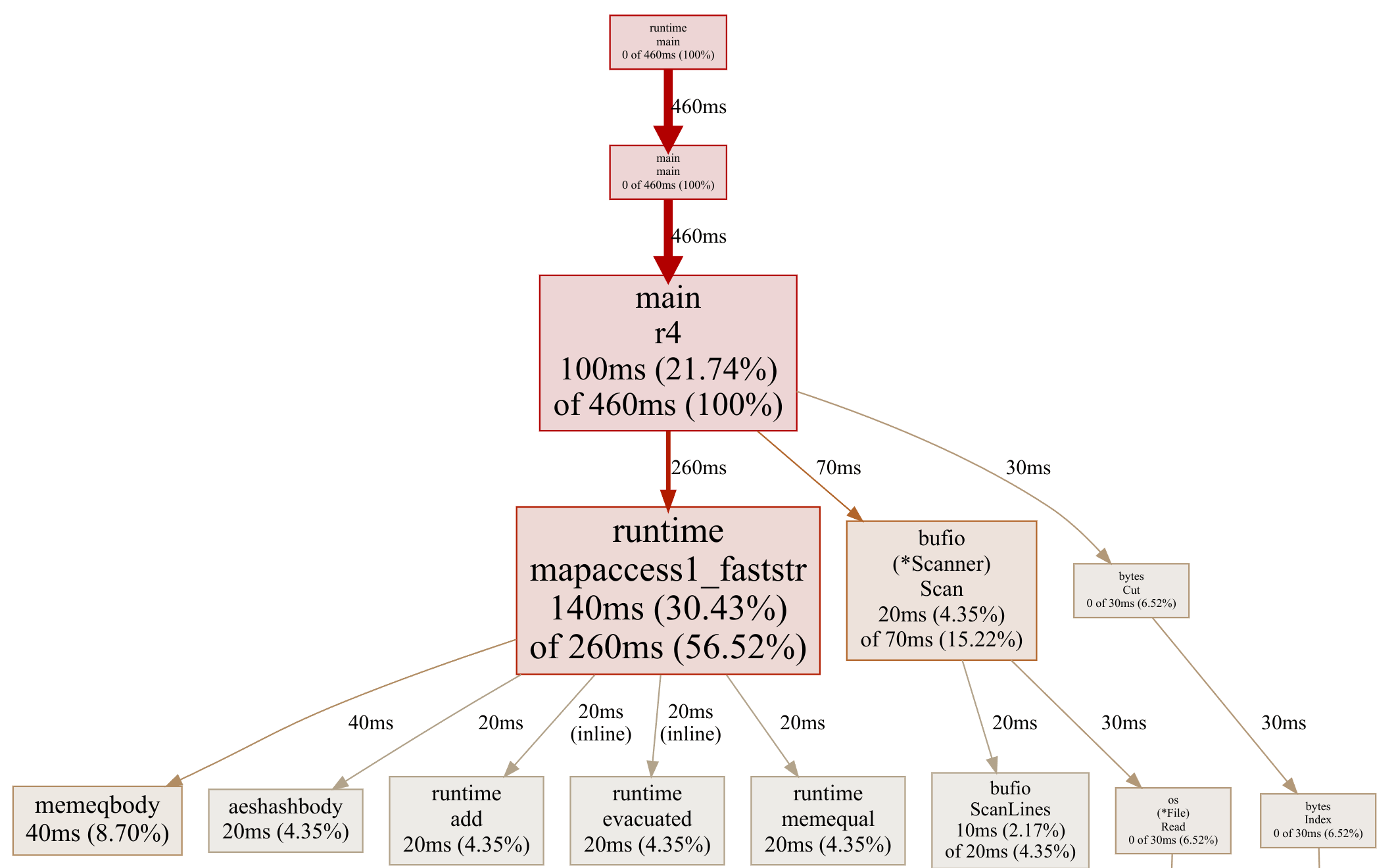
Okay, now it’s getting more durable. The plan operations dominate, and keen to a personalized hash desk will be slightly hard. So will removing the bufio.Scanner. Let’s procrastinate and find rid of the bytes.Minimize.
I belief to be a easy methodology to put time. If we seek for at a line, as an illustration:
It’s going to be faster to parse the temperature from the stay and gain the ';' there than to scan via the total set name to head searching to search out the ';'. This rather horrifying code does appropriate that:
stay := len(line)
tenths := int32(line[end-1] - '0')
ones := int32(line[end-3] - '0') // line[end-2] is '.'
var temp int32
var semicolon int
if line[end-4] == ';' { // clear N.N temperature
temp = ones*10 + tenths
semicolon = stay - 4
} else if line[end-4] == '-' { // harmful -N.N temperature
temp = -(ones*10 + tenths)
semicolon = stay - 5
} else {
tens := int32(line[end-4] - '0')
if line[end-5] == ';' { // clear NN.N temperature
temp = tens*100 + ones*10 + tenths
semicolon = stay - 5
} else { // harmful -NN.N temperature
temp = -(tens*100 + ones*10 + tenths)
semicolon = stay - 6
}
}
set := line[: semicolon]
Warding off bytes.Minimize slash the time down from 51.0 seconds to 46.0 seconds, one other little acquire.
Acknowledge 6: steer sure of bufio.Scanner
Now we’re going to study out to find rid of the bufio.Scanner. Must you watched about it, to search out the stay of each line, the scanner has to head searching to search out via the total bytes to search out the newline persona. Then we direction of many of the bytes as soon as more to parse the temperature and gain the ';'. So let’s are attempting to combine these steps and throw bufio.Scanner out the window.
In resolution 6 we allocate a 1MB buffer to learn the file in enormous chunks, seek for the last newline in the chunk to verify we’re not lowering a line in half of, and then direction of each chunk. That appears to be like fancy this:
buf := construct([]byte, 1024*1024)
readStart := 0
for {
n, err := f.Be taught(buf[readStart: ])
if err != nil && err != io.EOF {
return err
}
if readStart+n == 0 {
break
}
chunk := buf[: readStart+n]
newline := bytes.LastIndexByte(chunk, 'n')
if newline < 0 {
break
}
last := chunk[newline+1: ]
chunk = chunk[: newline+1]
for {
set, after, hasSemi := bytes.Minimize(chunk, []byte(";"))
// ... from right here, same temperature processing as r4 ...
Eradicating bufio.Scanner and doing our own scanning slash down the time from 46.0 seconds to 41.3 seconds. Yet one other little acquire, but I’ll take it.
Acknowledge 7: personalized hash desk
Acknowledge 7 is where we find actual. We’re going to put in pressure a personalized hash desk in favor to the explain of Plod’s plan. This has two advantages:
- We can hash the set name as we seek for the
';', averting processing bytes twice. - We can retailer each key in our hash desk as a byte slash, averting the have to convert each key to a
string(that will allocate and reproduction for each line).
I’ve written about easy learn how to put in pressure a hash desk in C, but I’ve also implemented a personalized “counter” hash desk in Plod, which is where I pulled this implementation from.
It’s a easy implementation that uses the FNV-1a hash algorithm with linear probing: if there’s a collision, explain the following empty slot.
To simplify, I appropriate pre-allocate a enormous selection of hash buckets (I’ve worn 100,000), to steer sure of attending to write common sense to resize the desk. My code will dismay if the desk will get better than half of fleshy. I measured that we find round 2% hash collisions.
It’s a bunch extra code this time – hash desk setup, the hashing itself, and the desk probing and insertion:
// The hash desk constructing:
model merchandise struct {
key []byte
stat *stats
}
items := construct([]merchandise, 100000) // hash buckets, linearly probed
dimension := 0 // selection of active items in items slash
buf := construct([]byte, 1024*1024)
readStart := 0
for {
// ... same chunking as r6 ...
for {
const (
// FNV-1 64-bit constants from hash/fnv.
offset64 = 14695981039346656037
high64 = 1099511628211
)
// Hash the set name and seek for ';'.
var set, after []byte
hash := uint64(offset64)
i := 0
for ; i < len(chunk); i++ {
c := chunk[i]
if c == ';' {
station = chunk[: i]
after = chunk[i+1: ]
break
}
hash ^= uint64(c) // FNV-1a is XOR then *
hash *= prime64
}
if i == len(chunk) {
break
}
// ... same temperature parsing as r6 ...
// Go to correct bucket in hash table.
hashIndex := int(hash & uint64(len(items)-1))
for {
if items[hashIndex].key == nil {
// Found empty slot, add new item (copying key).
key := make([]byte, len(station))
copy(key, station)
items[hashIndex] = item{
key: key,
stat: &stats{
min: temp,
max: temp,
sum: int64(temp),
count: 1,
},
}
size++
if size > len(items)/2 {
dismay("too many items in hash desk")
}
break
}
if bytes.Equal(items[hashIndex].key, set) {
// Found matching slot, add to current stats.
s := items[hashIndex].stat
s.min = min(s.min, temp)
s.max = max(s.max, temp)
s.sum += int64(temp)
s.count++
break
}
// Slot already holds one other key, are attempting next slot (linear probe).
hashIndex++
if hashIndex >= len(items) {
hashIndex = 0
}
}
}
readStart = reproduction(buf, last)
}
The payoff for all this code is enormous: the personalised hash desk cuts down the time from 41.3 seconds to 25.8s.
Acknowledge 8: direction of chunks in parallel
In resolution 8 I needed to add some parallelism. Alternatively, I belief I’d lope assist to the easy and idiomatic code from my first resolution, which uses bufio.Scanner and strconv.ParseFloat, and parallelise that. Then we can look whether optimising or parallelising gives better outcomes – and in resolution 9 we’ll attain each.
It’s straight-forward to parallelise a plan-lower self-discipline fancy this: split the file into the same-sized chunks (one for each CPU core), fireplace up a thread (in Plod, a goroutine) to direction of each chunk, and then merge the outcomes on the stay.
Here’s what that appears to be like fancy at a high level:
// Opt non-overlapping parts for file split (each fraction has offset and dimension).
parts, err := splitFile(inputPath, maxGoroutines)
if err != nil {
return err
}
// Originate a goroutine to direction of each fraction, returning outcomes on a channel.
resultsCh := construct(chan plan[string]r8Stats)
for _, fraction := fluctuate parts {
lope r8ProcessPart(inputPath, fraction.offset, fraction.dimension, resultsCh)
}
// Preserve up for the outcomes to reach assist assist in and combination them.
totals := construct(plan[string]r8Stats)
for i := 0; i < len(parts); i++ {
consequence := <-resultsCh
for set, s := fluctuate consequence {
ts, ok := totals[station]
if !ok {
totals[station] = r8Stats{
min: s.min,
max: s.max,
sum: s.sum,
count: s.count,
}
continue
}
ts.min = min(ts.min, s.min)
ts.max = max(ts.max, s.max)
ts.sum += s.sum
ts.count += s.count
totals[station] = ts
}
}
The splitFile operate is slightly behind, so I gained’t consist of it right here. It looks to be on the dimensions of the file, divides that by the selection of parts we need, and then seeks to each fraction, reading 100 bytes ahead of the stay and searching out for the last newline to verify each fraction ends with a fleshy line.
The r8ProcessPart operate is admittedly akin to the r1 resolution, but it begins by searching for to the fraction offset and limiting the length to the fraction dimension (the explain of io.LimitedReader). When it’s done, it sends its own stats plan assist on the channel:
func r8ProcessPart(inputPath string, fileOffset, fileSize int64,
resultsCh chan plan[string]r8Stats) {
file, err := os.Open(inputPath)
if err != nil {
dismay(err)
}
defer file.Conclude()
_, err = file.Search(fileOffset, io.SeekStart)
if err != nil {
dismay(err)
}
f := io.LimitedReader{R: file, N: fileSize}
stationStats := construct(plan[string]r8Stats)
scanner := bufio.NewScanner(&f)
for scanner.Scan() {
// ... same processing as r1 ...
}
resultsCh <- stationStats
}
Processing the enter file in parallel gives a tall acquire over r1, taking the time from 1 minute 45 seconds to 24.3 seconds. For comparison, the old “optimised non-parallel” model, resolution 7, took 25.8 seconds. So for this case, parallelisation is slightly faster than optimisation – and rather slightly extra rapid-witted.
Acknowledge 9: all optimisations plus parallelisation
For resolution 9, our last are attempting, we’ll simply combine the total old optimisations from r1 via r7 with the parallelisation we did in r8.
I’ve worn the same splitFile operate from r8, and the rest of the code is appropriate copied from r7, so there’s nothing fresh to sign right here. Other than the outcomes … this last model slash down the time from 24.3 seconds to 3.99 seconds, a tall acquire.
Interestingly, because the total actual processing is now in one well-known operate, r9ProcessPart, the profile graph will not be any longer namely precious. Here’s what it looks to be fancy now:
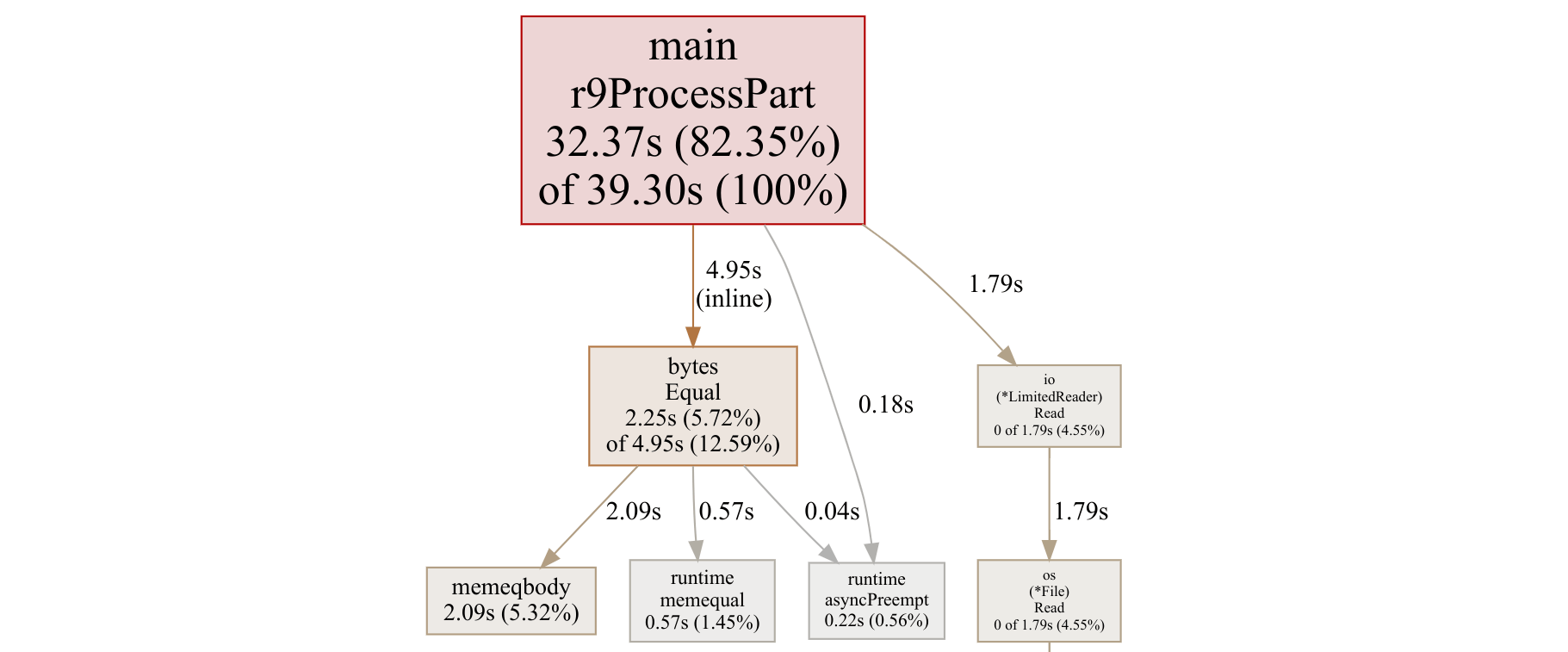
As which that it’s doubtless you’ll look, 82% of the time is being spent in r9ProcessPart, with bytes.Equal taking 13%, and the file reading taking the last 5%.
If we favor to profile extra, now we favor to dive deeper than the operate level that the graph gape gives us, and explain the source gape. Here’s the interior loop:

I gain this document confusing. Why does if items[hashIndex].key == nil sign as taking 5.01s, however the decision to bytes.Equal reveals as easiest 390ms. Absolutely a slash lookup is some distance much less dear than a operate name? Must which that it’s doubtless you’ll very smartly be a Plod efficiency knowledgeable and can abet me define it, I’m all ears!
At the least, I’m sure there are crazier optimisations I could attain, but I made up my mind I’d lope away it there. Processing a billion rows in 4 seconds, or 250 million rows per 2nd, used to be correct sufficient for me.
Table of outcomes
Below is a desk of all my Plod solutions in one problem, along with the fastest Plod and fastest Java solutions. Every consequence is the most easy-of-five time for working the resolution towards the same billion-row enter.
| Model | Summary | Time | Times as snappy as r1 |
|---|---|---|---|
| r1 | easy and idiomatic | 1m45 | 1.00 |
| r2 | plan with pointer values | 1m31 | 1.15 |
| r3 | parse temperatures by hand | 55.8s | 1.87 |
| r4 | mounted level integers | 51.0s | 2.05 |
| r5 | steer sure of bytes.Minimize |
46.0s | 2.27 |
| r6 | steer sure of bufio.Scanner |
41.3s | 2.53 |
| r7 | personalized hash desk | 25.8s | 4.05 |
| r8 | parallelise r1 | 24.3s | 4.31 |
| r9 | parallelise r7 | 3.99s | 26.2 |
| AY | fastest Plod model | 2.90s | 36.2 |
| TW | fastest Java model | 0.953s | 110 |
I’m in the same ballpark as Alexander Yastrebov’s Plod model. His resolution looks to be a lot like mine: break the file into chunks, explain a personalized hash desk (he even uses FNV hashing), and parse temperatures as integers. Alternatively, he uses reminiscence-mapped files, which I’d dominated out for portability causes – I’m guessing that’s why his is slightly faster.
Thomas Wuerthinger (with credit ranking to others) created the fastest total resolution to the long-established self-discipline in Java. His runs in below a 2nd on my machine, 4x as snappy as my Plod model. In addition to to parallel processing and reminiscence-mapped files, it looks to be fancy he’s the explain of unrolled loops, non-branching parsing code, and other low-level tricks.
It looks to be fancy Thomas is the founder of and a critical contributor to GraalVM, a faster Java Virtual Machine with ahead-of-time compilation. So he’s certainly an knowledgeable in his arena. Good work Thomas and co!
Does any of this topic?
For nearly all of day-to-day programming projects, easy and idiomatic code is in general the most easy problem to initiate. Must you’re calculating statistics over a billion temperatures, and likewise you appropriate need the acknowledge as soon as, 1 minute 45 seconds is doubtlessly goal.
However when you’re constructing a records processing pipeline, when which that it’s doubtless you’ll construct your code 4 occasions as snappy, or even 26 occasions as snappy, you’ll not easiest construct customers happier, you’ll put loads on compute costs – if the system is being smartly loaded, your compute costs would possibly very smartly be 1/4 or 1/26 of the long-established!
Or, when you’re constructing a runtime fancy GraalVM, or an interpreter fancy my GoAWK, this level of efficiency in reality does topic: when you lag up the interpreter, your entire customers’ programs gallop that well-known faster too.
Plus, it’s appropriate enjoyable writing code that will get the most out of your machine.
I’d esteem it when you backed me on GitHub – this would possibly increasingly well motivate me to work on my starting up source projects and write extra correct relate material. Thanks!